Engineering AI Agents
BOOK
Initial notebooks expected Sept 2025
COURSES
Introduction to AI
AI for Robotics
Deep Learning for Computer Vision
DATA MINING - BEING PORTED
ABOUT ME
Markov Decision Processes
Markov Decision Processes
Optimal Fully Observed Sequential Decision Making
Syllabus
Syllabus
Foundations
Rules, rule the world
AI Agents
The four approaches towards AI
Data Science 360
The Learning Problem
Linear Regression
Optimization Algorithms
Entropy
Maximum Likelihood Estimation of a marginal model
Maximum Likelihood Estimation of Gaussian Parameters
Maximum Likelihood (ML) Estimation of conditional models
Introduction to Classification
Logistic Regression
Deep Neural Networks
Introduction to Backpropagation
Backpropagation in Deep Neural Networks
Backpropagation DNN exercises
Fashion MNIST Case Study
Regularization in Deep Neural Networks
Batch Normalization
Perception & Scene Understanding
Introduction to Convolutional Neural Networks
CNN Layers
CNN Example Architectures
Using convnets with small datasets
Visualizing what convnets learn
Feature Extraction via Residual Networks
Introduction to Scene Understanding
Object Detection
Object Detection and Semantic Segmentation Metrics
Region-CNN (RCNN) Object Detection
Fast and Faster RCNN Object Detection
Object Detection & Semantic Segmentation Workshop
Mask R-CNN Semantic Segmentation
Mask R-CNN Demo
Mask R-CNN - Inspect Training Data
Mask R-CNN - Inspect Trained Model
Mask R-CNN - Inspect Weights of a Trained Model
Detectron2 Beginner’s Tutorial
Introduction to Transfer Learning
Transfer Learning for Computer Vision Tutorial
Recursive State Estimation
Discrete Bayes Filter
Localization and Tracking
Kalman Filters
Large Language Models
Introduction to Recurrent Neural Networks (RNN)
Simple RNN
The Long Short-Term Memory (LSTM) Architecture
Time Series Prediction using RNNs
Introduction to NLP Pipelines
Tokenization
Word2Vec Embeddings
Word2Vec from scratch
Word2Vec Tensorflow Tutorial
Language Models
CNN Language Model
Simple RNN Language Model
LSTM Language Model from scratch
RNN-based Neural Machine Translation
Character-level recurrent sequence-to-sequence model
NMT Metrics - BLEU
Attention in RNN-based NMT
Transformers and Self-Attention
Single-head self-attention
Multi-head self-attention
Positional Embeddings
Logical Reasoning
Automated Reasoning
World Models
Logical Inference
Logical Agents
Planning without Interactions
Automated Planning
Planning Domain Definition Language (PDDL)
The Unified Planning Library
Logistics Planning in PDDL
Manufacrturing Robot Planning in PDDL
Planning with Search
Forward Search Algorithms
The A* Algorithm
Interactive Demo
Motion Planning for Autonomous Cars
Acting - Markov Decision Processes
Markov Decision Processes
Introduction to MDP
Bellman Expectation Backup
Policy Evaluation (Prediction)
Bellman Optimality Backup
Policy Improvement (Control)
MDP Dynamic Programming Algorithms
Policy Iteration
Value Iteration
MDP Workshop
Cleaning Robot - Deterministic MDP
Cleaning Robot - Stochastic MDP
The recycling robot.
Acting - Reinforcement Learning
Reinforcement Learning
Monte-Carlo Prediction
Temporal Difference (TD) Prediction
Model-free control
Generalized Policy Iteration
\(\epsilon\)
-greedy Monte-Carlo (MC) Control
The SARSA Algorithm
SARSA Gridworld Example
Math Background
Math for ML Textbook
Probability Basics
Linear Algebra for Machine Learning
Calculus
Resources
Your Programming Environment
Training Keras with the SLURM Scheduler
NYU JupyrterHub Environments
Submitting Your Assignment / Project
Learn Python
Assignments
Project
Categories
All
(8)
\(\epsilon\)
-greedy Monte-Carlo (MC) Control
In this section we outline methods that can result in optimal policies when the MDP is
unknown
and we need to
learn
its underlying functions / models - also known as the
mode…
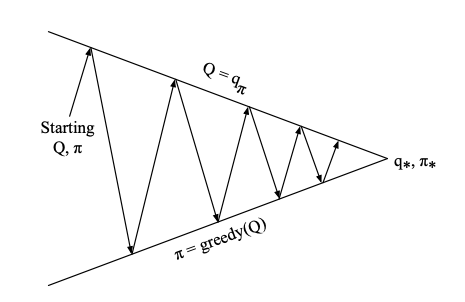
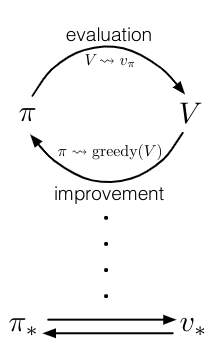
Generalized Policy Iteration
As we saw in the dynamic programming (DP) solution MDP problem, policy iteration is an algorithm that consists of two simultaneous, interacting processes: one making the…
Model-free control
Monte-Carlo Prediction
In this chapter we find optimal policy solutions when the MDP is
unknown
and we need to
learn
its underlying value functions - also known as the
model free
prediction…
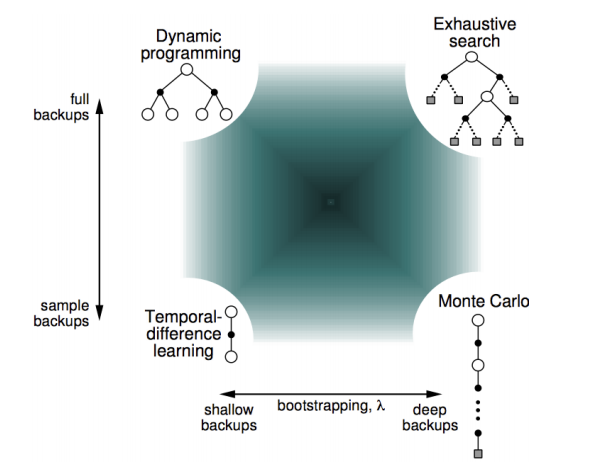
Reinforcement Learning
Different Approaches to solve known and unknown MDPs
Temporal Difference (TD) Prediction
If one had to identify one idea as central and novel to reinforcement learning, it would undoubtedly be temporal-difference(TD) learning. TD learning is a combination of…
The SARSA Algorithm
SARSA implements a
\(Q(s,a)\)
value-based GPI and naturally follows as an enhancement from the
\(\epsilon-greedy\)
policy improvement step of MC control.
No matching items
Back to top