Language Models
These notes heavily borrowing from the CS224N set of notes on Language Models.
The need for neural language models
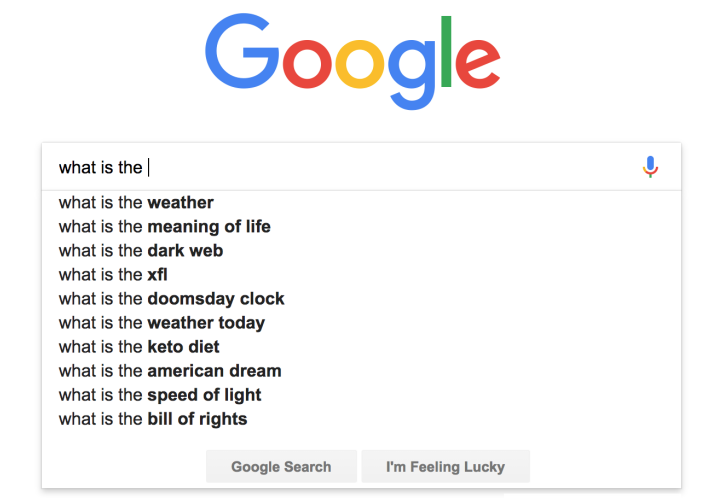 *Language model example that completes the search query. We need a language model that given a sequence of words \(\{ \mathbf w_1, ..., \mathbf w_t \}\) it returns
*Language model example that completes the search query. We need a language model that given a sequence of words \(\{ \mathbf w_1, ..., \mathbf w_t \}\) it returns
\[p(\mathbf w_{t+1} | \mathbf w_1, ..., \mathbf w_t)\]
Language models in general compute the probability of occurrence of a number of words in a particular sequence. How we can build language models though ?
The probability of a sequence of \(m\) words \(\{\mathbf w_1, ..., \mathbf w_m \}\) is denoted as \(p(\mathbf w_1,...,\mathbf w_m)\). For example the probability of the sentence “The cat sat on the mat” is \(p(\text{The}, \text{cat}, \text{sat}, \text{on}, \text{the}, \text{mat})\).
We can simply use the chain rule of probability to compute the probability of a sequence of words without making any assumptions about the structure of the language. For example, the probability of the sentence “The cat sat on the mat” is:
\[p(\text{The}, \text{cat}, \text{sat}, \text{on}, \text{the}, \text{mat}) = p(\text{The}) p(\text{cat} | \text{The}) p(\text{sat} | \text{The}, \text{cat}) p(\text{on} | \text{cat}, \text{sat}) p(\text{the} | \text{sat}, \text{on}) p(\text{mat} | \text{on}, \text{the})\]
In general,
\[ p(\mathbf w_1,...,\mathbf w_m) = \prod_{i=1}^{i=m} p(\mathbf w_{i} | \mathbf w_1, ..., \mathbf w_{i-1})\]
Since the counting of all these probabilities is intractable, we will use a simpler model that makes some assumptions about the structure of the language. The assumption we usually make is that the probability of a word depends only on a fixed number of previous words. For example, we can assume that the probability of a word depends only on the previous n-words. This assumption is called the n-gram assumption.
\[ p(\mathbf w_1,...,\mathbf w_m) \approx \prod_{i=1}^{i=m} p(\mathbf w_{i} | \mathbf w_{i-1}, ..., \mathbf w_{i-n+1})\]
To compute these probabilities, the count of each n-gram would be compared against the frequency of each word. For instance, if the model takes bi-grams, the frequency of each bi-gram, calculated via combining a word with its previous word, would be divided by the frequency of the corresponding unigram. For example for bi-gram and trigram models the above equation becomes:
\[p(\mathbf w_2 | \mathbf w_1) = \dfrac {count(\mathbf w_1,\mathbf w_2)}{count(\mathbf w_1)}\]
\[p(\mathbf w_3 | \mathbf w_1, \mathbf w_2) = \dfrac {count(\mathbf w_1, \mathbf w_2, \mathbf w_3)}{count(\mathbf w_1, \mathbf w_2)}\]
Counting these probabilities is notoriously space (memory) inefficient as we need to store the counts for all possible grams in the corpus. At the same time, when we have no events in the denominators to count we have no possibility of estimating such probabilities (the so-called sparsity problem).
To solve these issues we will create neural models that are able to predict the required word.