import tensorflow as tffrom tensorflow.keras import backend as Ktf.keras.__version__
2023-10-12 14:55:34.307312: I tensorflow/core/platform/cpu_feature_guard.cc:194] This TensorFlow binary is optimized with oneAPI Deep Neural Network Library (oneDNN) to use the following CPU instructions in performance-critical operations: SSE3 SSE4.1 SSE4.2 AVX
To enable them in other operations, rebuild TensorFlow with the appropriate compiler flags.
2023-10-12 14:55:34.407246: I tensorflow/core/util/port.cc:104] oneDNN custom operations are on. You may see slightly different numerical results due to floating-point round-off errors from different computation orders. To turn them off, set the environment variable `TF_ENABLE_ONEDNN_OPTS=0`.
'2.11.0'
This notebook contains the code sample found in Chapter 5, Section 4 of Deep Learning with Python. Note that the original text features far more content, in particular further explanations and figures: in this notebook, you will only find source code and related comments.
It is often said that deep learning models are “black boxes”, learning representations that are difficult to extract and present in a human-readable form. While this is partially true for certain types of deep learning models, it is definitely not true for convnets. The representations learned by convnets are highly amenable to visualization, in large part because they are representations of visual concepts. Since 2013, a wide array of techniques have been developed for visualizing and interpreting these representations. We won’t survey all of them, but we will cover three of the most accessible and useful ones:
Visualizing intermediate convnet outputs (“intermediate activations”). This is useful to understand how successive convnet layers transform their input, and to get a first idea of the meaning of individual convnet filters.
Visualizing convnets filters. This is useful to understand precisely what visual pattern or concept each filter in a convnet is receptive to.
Visualizing heatmaps of class activation in an image. This is useful to understand which part of an image where identified as belonging to a given class, and thus allows to localize objects in images.
For the first method – activation visualization – we will use the small convnet that we trained from scratch on the cat vs. dog classification problem two sections ago. For the next two methods, we will use the VGG16 model that we introduced in the previous section.
Visualizing intermediate activations
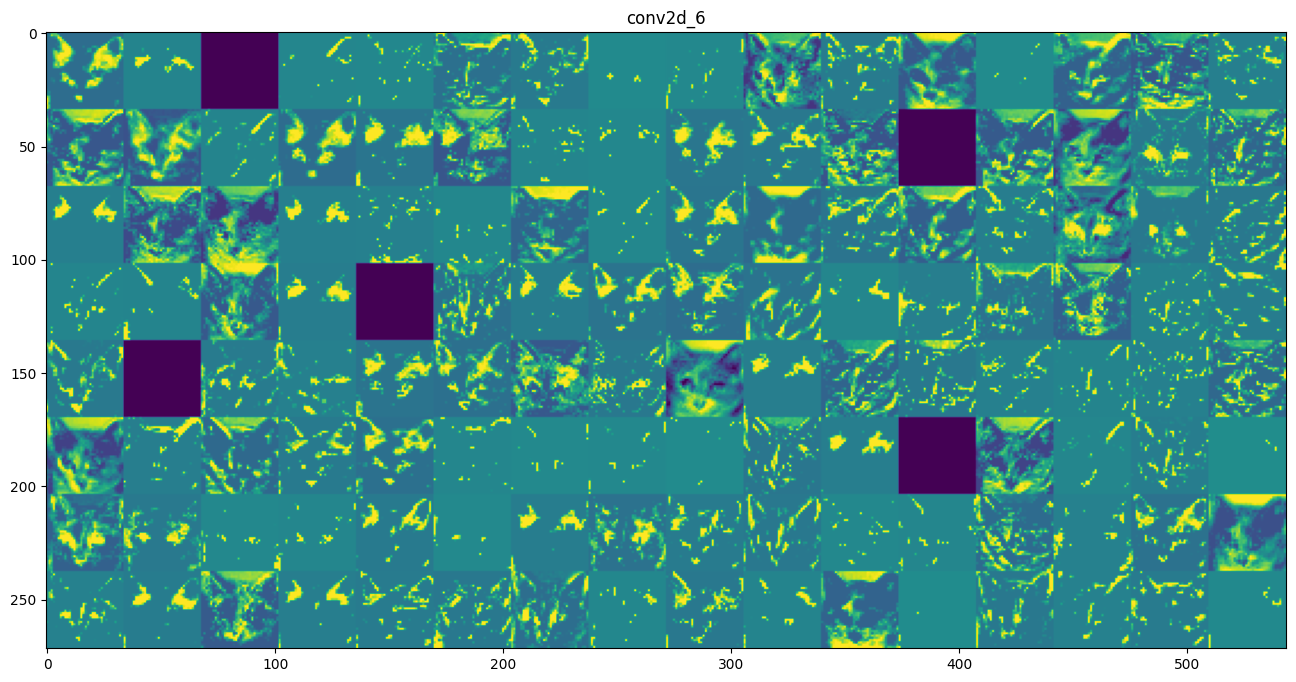
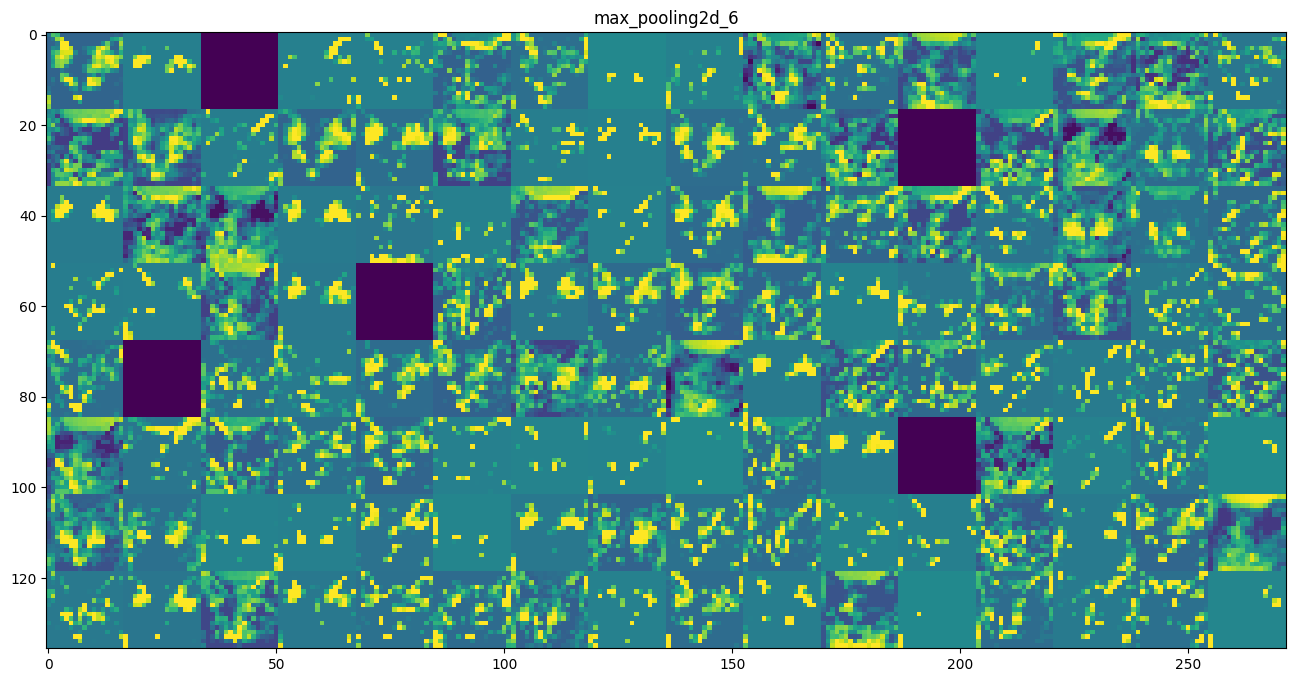
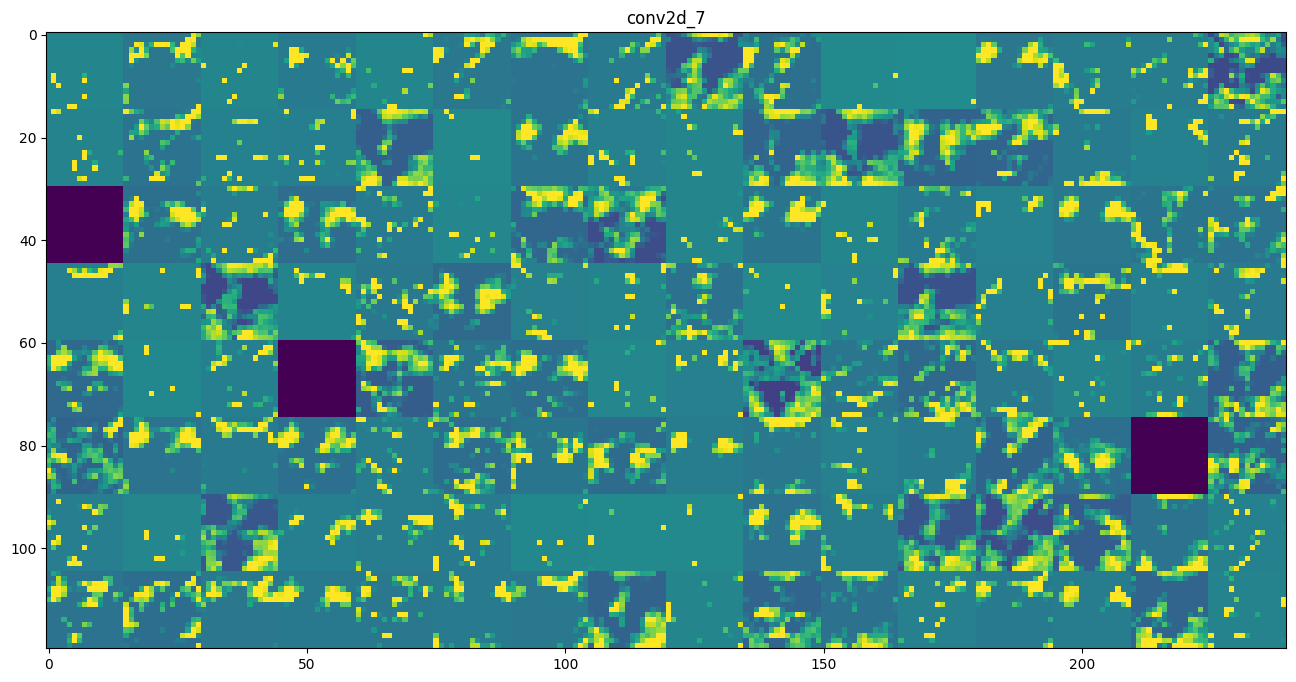
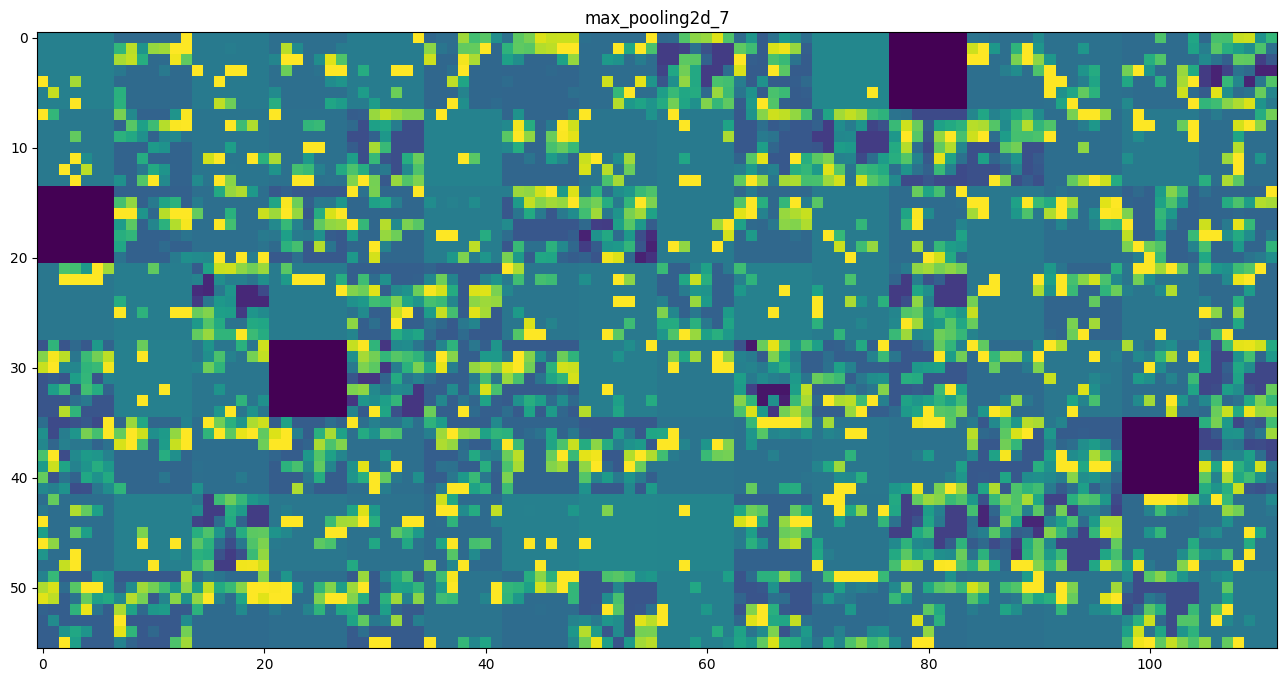
Visualizing intermediate activations consists in displaying the feature maps that are output by various convolution and pooling layers in a network, given a certain input (the output of a layer is often called its “activation”, the output of the activation function). This gives a view into how an input is decomposed unto the different filters learned by the network. These feature maps we want to visualize have 3 dimensions: width, height, and depth (channels). Each channel encodes relatively independent features, so the proper way to visualize these feature maps is by independently plotting the contents of every channel, as a 2D image. Let’s start by loading the model that we saved in section 5.2:
#from tf.keras import load_modelmodel = tf.keras.models.load_model('cats_and_dogs_small_2.h5')model.summary() # As a reminder.
2023-10-12 14:55:35.660142: I tensorflow/compiler/xla/stream_executor/cuda/cuda_gpu_executor.cc:998] successful NUMA node read from SysFS had negative value (-1), but there must be at least one NUMA node, so returning NUMA node zero
2023-10-12 14:55:35.716937: I tensorflow/compiler/xla/stream_executor/cuda/cuda_gpu_executor.cc:998] successful NUMA node read from SysFS had negative value (-1), but there must be at least one NUMA node, so returning NUMA node zero
2023-10-12 14:55:35.717085: I tensorflow/compiler/xla/stream_executor/cuda/cuda_gpu_executor.cc:998] successful NUMA node read from SysFS had negative value (-1), but there must be at least one NUMA node, so returning NUMA node zero
2023-10-12 14:55:35.717496: I tensorflow/core/platform/cpu_feature_guard.cc:194] This TensorFlow binary is optimized with oneAPI Deep Neural Network Library (oneDNN) to use the following CPU instructions in performance-critical operations: SSE3 SSE4.1 SSE4.2 AVX
To enable them in other operations, rebuild TensorFlow with the appropriate compiler flags.
2023-10-12 14:55:35.718858: I tensorflow/compiler/xla/stream_executor/cuda/cuda_gpu_executor.cc:998] successful NUMA node read from SysFS had negative value (-1), but there must be at least one NUMA node, so returning NUMA node zero
2023-10-12 14:55:35.718994: I tensorflow/compiler/xla/stream_executor/cuda/cuda_gpu_executor.cc:998] successful NUMA node read from SysFS had negative value (-1), but there must be at least one NUMA node, so returning NUMA node zero
2023-10-12 14:55:35.719061: I tensorflow/compiler/xla/stream_executor/cuda/cuda_gpu_executor.cc:998] successful NUMA node read from SysFS had negative value (-1), but there must be at least one NUMA node, so returning NUMA node zero
2023-10-12 14:55:35.773521: I tensorflow/compiler/xla/stream_executor/cuda/cuda_gpu_executor.cc:998] successful NUMA node read from SysFS had negative value (-1), but there must be at least one NUMA node, so returning NUMA node zero
2023-10-12 14:55:35.773649: I tensorflow/compiler/xla/stream_executor/cuda/cuda_gpu_executor.cc:998] successful NUMA node read from SysFS had negative value (-1), but there must be at least one NUMA node, so returning NUMA node zero
2023-10-12 14:55:35.773719: I tensorflow/compiler/xla/stream_executor/cuda/cuda_gpu_executor.cc:998] successful NUMA node read from SysFS had negative value (-1), but there must be at least one NUMA node, so returning NUMA node zero
2023-10-12 14:55:35.773791: I tensorflow/core/common_runtime/gpu/gpu_device.cc:1621] Created device /job:localhost/replica:0/task:0/device:GPU:0 with 1415 MB memory: -> device: 0, name: NVIDIA RTX A4500 Laptop GPU, pci bus id: 0000:01:00.0, compute capability: 8.6
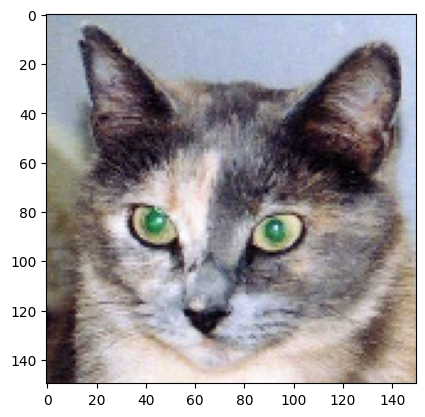
This will be the input image we will use – a picture of a cat, not part of images that the network was trained on:
img_path ='dogscats/subset/test/cats/cat.1700.jpg'# We preprocess the image into a 4D tensor#from keras.preprocessing import imageimport numpy as npimg = tf.keras.utils.load_img(img_path, target_size=(150, 150))img_tensor = tf.keras.utils.img_to_array(img)img_tensor = np.expand_dims(img_tensor, axis=0)# Remember that the model was trained on inputs# that were preprocessed in the following way:img_tensor /=255.# Its shape is (1, 150, 150, 3)print(img_tensor.shape)
(1, 150, 150, 3)
Let’s display our picture:
import matplotlib.pyplot as pltplt.imshow(img_tensor[0])plt.show()
In order to extract the feature maps we want to look at, we will create a Keras model that takes batches of images as input, and outputs the activations of all convolution and pooling layers. To do this, we will use the Keras class Model. A Model is instantiated using two arguments: an input tensor (or list of input tensors), and an output tensor (or list of output tensors). The resulting class is a Keras model, just like the Sequential models that you are familiar with, mapping the specified inputs to the specified outputs. What sets the Model class apart is that it allows for models with multiple outputs, unlike Sequential. For more information about the Model class, see Chapter 7, Section 1.
# Extracts the outputs of the top 8 layers:layer_outputs = [layer.output for layer in model.layers[:8]]# Creates a model that will return these outputs, given the model input:activation_model = tf.keras.models.Model(inputs=model.input, outputs=layer_outputs)
When fed an image input, this model returns the values of the layer activations in the original model. This is the first time you encounter a multi-output model in this book: until now the models you have seen only had exactly one input and one output. In the general case, a model could have any number of inputs and outputs. This one has one input and 8 outputs, one output per layer activation.
# This will return a list of 5 Numpy arrays:# one array per layer activationactivations = activation_model.predict(img_tensor)
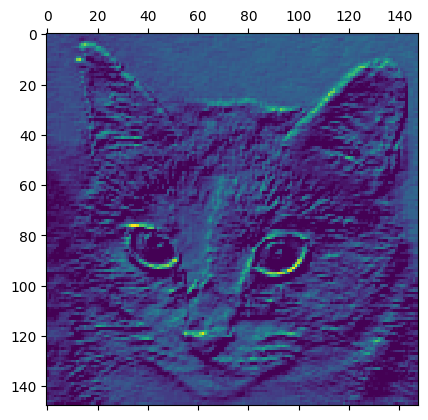
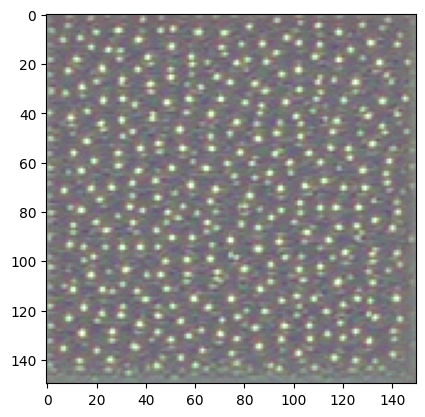
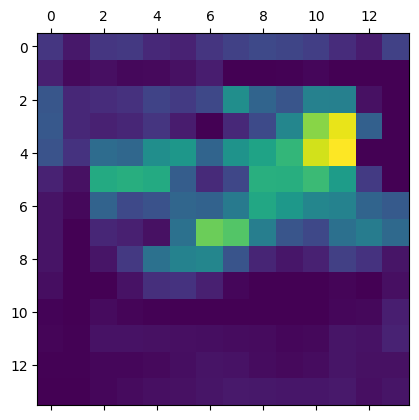
It’s a 148x148 feature map with 32 channels. Let’s try visualizing the 3rd channel:
import matplotlib.pyplot as pltplt.matshow(first_layer_activation[0, :, :, 3], cmap='viridis')plt.show()
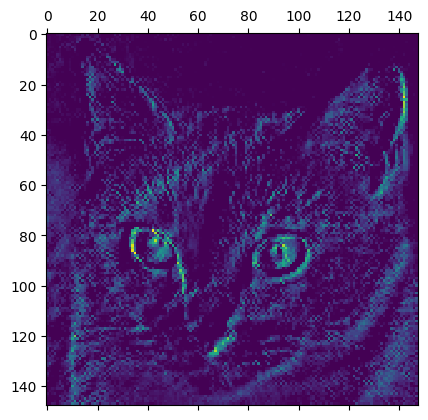
This channel appears to encode a diagonal edge detector. Let’s try the 30th channel – but note that your own channels may vary, since the specific filters learned by convolution layers are not deterministic.
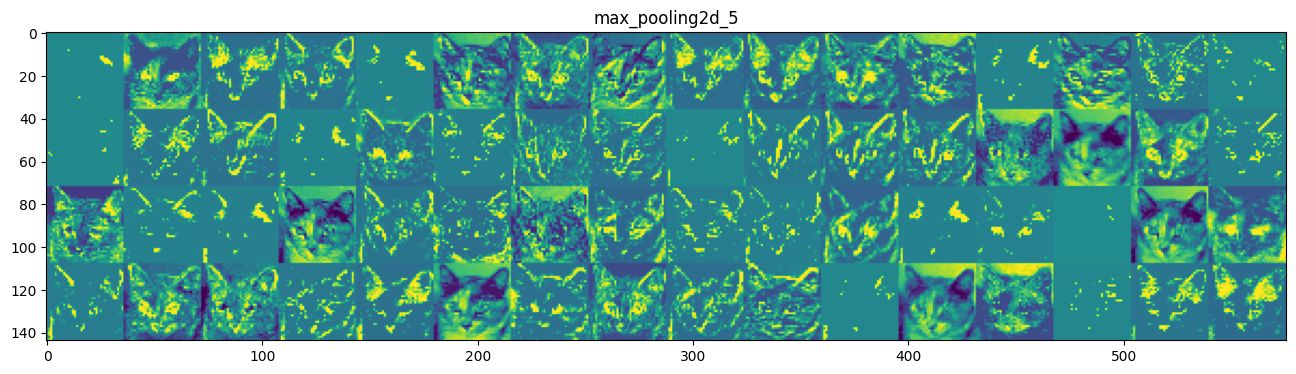
This one looks like a “bright green dot” detector, useful to encode cat eyes. At this point, let’s go and plot a complete visualization of all the activations in the network. We’ll extract and plot every channel in each of our 8 activation maps, and we will stack the results in one big image tensor, with channels stacked side by side.
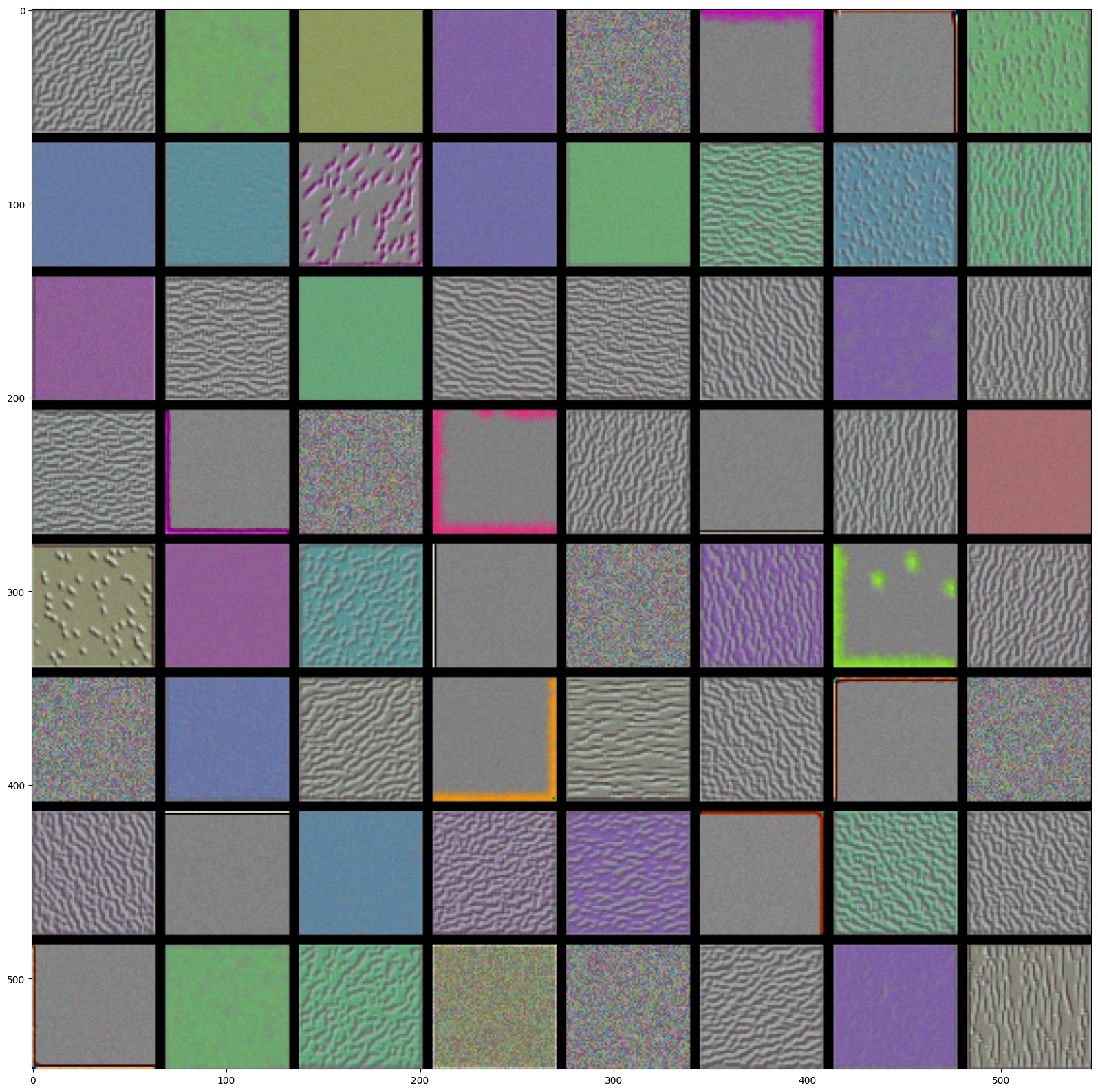
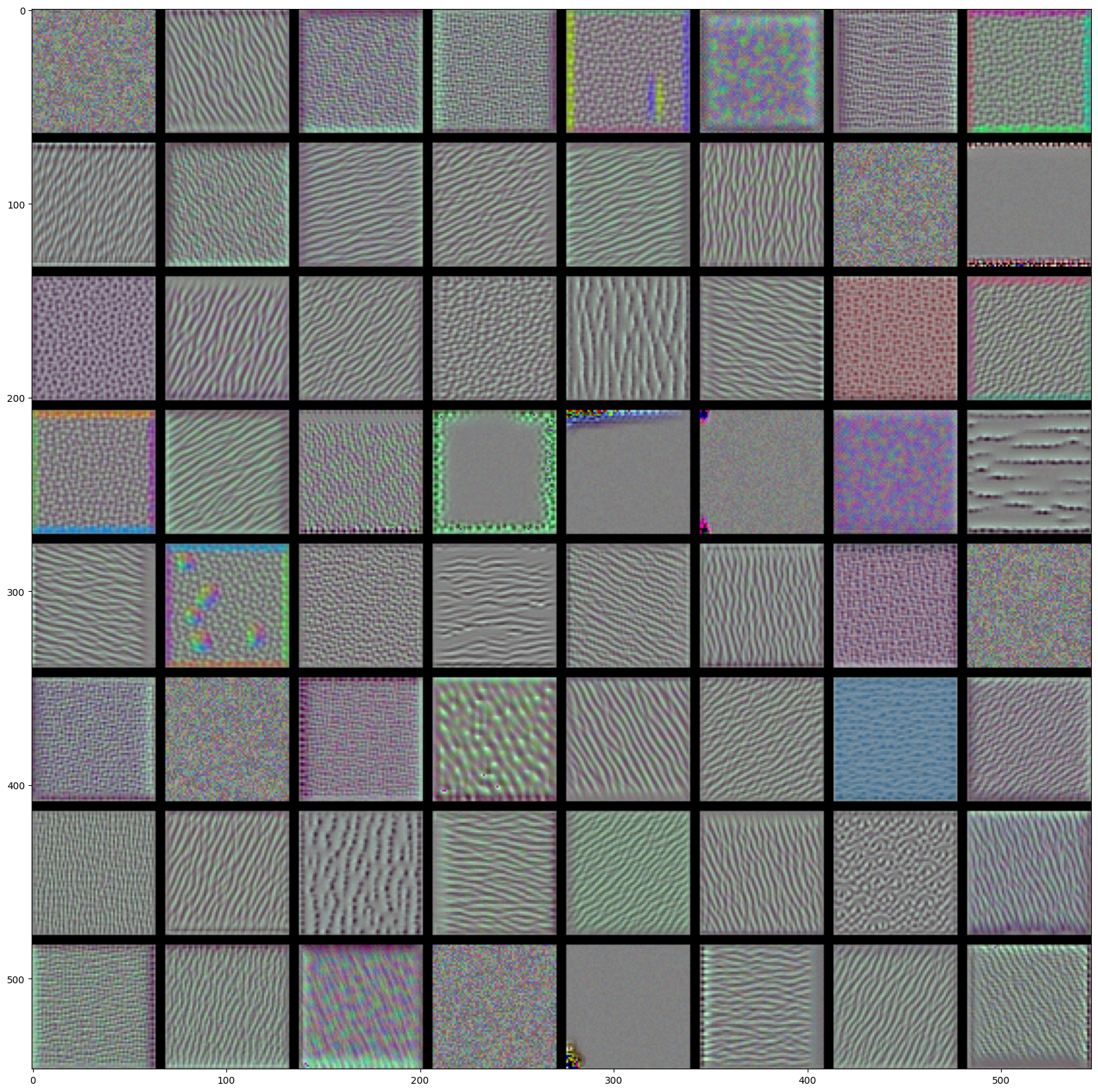
# These are the names of the layers, so can have them as part of our plotlayer_names = []for layer in model.layers[:8]: layer_names.append(layer.name)images_per_row =16# Now let's display our feature mapsfor layer_name, layer_activation inzip(layer_names, activations):# This is the number of features in the feature map n_features = layer_activation.shape[-1]# The feature map has shape (1, size, size, n_features) size = layer_activation.shape[1]# We will tile the activation channels in this matrix n_cols = n_features // images_per_row display_grid = np.zeros((size * n_cols, images_per_row * size))# We'll tile each filter into this big horizontal gridfor col inrange(n_cols):for row inrange(images_per_row): channel_image = layer_activation[0, :, :, col * images_per_row + row]# Post-process the feature to make it visually palatable channel_image -= channel_image.mean() channel_image /= channel_image.std() channel_image *=64 channel_image +=128 channel_image = np.clip(channel_image, 0, 255).astype('uint8') display_grid[col * size : (col +1) * size, row * size : (row +1) * size] = channel_image# Display the grid scale =1./ size plt.figure(figsize=(scale * display_grid.shape[1], scale * display_grid.shape[0])) plt.title(layer_name) plt.grid(False) plt.imshow(display_grid, aspect='auto', cmap='viridis')plt.show()
/tmp/ipykernel_38466/3924288684.py:28: RuntimeWarning: invalid value encountered in true_divide
channel_image /= channel_image.std()
A few remarkable things to note here:
The first layer acts as a collection of various edge detectors. At that stage, the activations are still retaining almost all of the information present in the initial picture.
As we go higher-up, the activations become increasingly abstract and less visually interpretable. They start encoding higher-level concepts such as “cat ear” or “cat eye”. Higher-up presentations carry increasingly less information about the visual contents of the image, and increasingly more information related to the class of the image.
The sparsity of the activations is increasing with the depth of the layer: in the first layer, all filters are activated by the input image, but in the following layers more and more filters are blank. This means that the pattern encoded by the filter isn’t found in the input image.
We have just evidenced a very important universal characteristic of the representations learned by deep neural networks: the features extracted by a layer get increasingly abstract with the depth of the layer. The activations of layers higher-up carry less and less information about the specific input being seen, and more and more information about the target (in our case, the class of the image: cat or dog). A deep neural network effectively acts as an information distillation pipeline, with raw data going in (in our case, RBG pictures), and getting repeatedly transformed so that irrelevant information gets filtered out (e.g. the specific visual appearance of the image) while useful information get magnified and refined (e.g. the class of the image).
This is analogous to the way humans and animals perceive the world: after observing a scene for a few seconds, a human can remember which abstract objects were present in it (e.g. bicycle, tree) but could not remember the specific appearance of these objects. In fact, if you tried to draw a generic bicycle from mind right now, chances are you could not get it even remotely right, even though you have seen thousands of bicycles in your lifetime. Try it right now: this effect is absolutely real. You brain has learned to completely abstract its visual input, to transform it into high-level visual concepts while completely filtering out irrelevant visual details, making it tremendously difficult to remember how things around us actually look.
Visualizing convnet filters
Another easy thing to do to inspect the filters learned by convnets is to display the visual pattern that each filter is meant to respond to. This can be done with gradient ascent in input space: applying gradient descent to the value of the input image of a convnet so as to maximize the response of a specific filter, starting from a blank input image. The resulting input image would be one that the chosen filter is maximally responsive to.
The process is simple: we will build a loss function that maximizes the value of a given filter in a given convolution layer, then we will use stochastic gradient descent to adjust the values of the input image so as to maximize this activation value. For instance, here’s a loss for the activation of filter 0 in the layer “block3_conv1” of the VGG16 network, pre-trained on ImageNet:
Downloading data from https://storage.googleapis.com/tensorflow/keras-applications/vgg16/vgg16_weights_tf_dim_ordering_tf_kernels_notop.h5
58889256/58889256 [==============================] - 1s 0us/step
2023-10-12 14:55:39.315120: I tensorflow/compiler/xla/stream_executor/cuda/cuda_gpu_executor.cc:998] successful NUMA node read from SysFS had negative value (-1), but there must be at least one NUMA node, so returning NUMA node zero
2023-10-12 14:55:39.315290: I tensorflow/compiler/xla/stream_executor/cuda/cuda_gpu_executor.cc:998] successful NUMA node read from SysFS had negative value (-1), but there must be at least one NUMA node, so returning NUMA node zero
2023-10-12 14:55:39.315360: I tensorflow/compiler/xla/stream_executor/cuda/cuda_gpu_executor.cc:998] successful NUMA node read from SysFS had negative value (-1), but there must be at least one NUMA node, so returning NUMA node zero
2023-10-12 14:55:39.315460: I tensorflow/compiler/xla/stream_executor/cuda/cuda_gpu_executor.cc:998] successful NUMA node read from SysFS had negative value (-1), but there must be at least one NUMA node, so returning NUMA node zero
2023-10-12 14:55:39.315532: I tensorflow/compiler/xla/stream_executor/cuda/cuda_gpu_executor.cc:998] successful NUMA node read from SysFS had negative value (-1), but there must be at least one NUMA node, so returning NUMA node zero
2023-10-12 14:55:39.315595: I tensorflow/core/common_runtime/gpu/gpu_device.cc:1621] Created device /job:localhost/replica:0/task:0/device:GPU:0 with 1415 MB memory: -> device: 0, name: NVIDIA RTX A4500 Laptop GPU, pci bus id: 0000:01:00.0, compute capability: 8.6
2023-10-12 14:55:39.322210: I tensorflow/compiler/mlir/mlir_graph_optimization_pass.cc:357] MLIR V1 optimization pass is not enabled
2023-10-12 14:55:39.349496: W tensorflow/c/c_api.cc:291] Operation '{name:'block4_conv1/bias/Assign' id:191 op device:{requested: '', assigned: ''} def:{{{node block4_conv1/bias/Assign}} = AssignVariableOp[_has_manual_control_dependencies=true, dtype=DT_FLOAT, validate_shape=false](block4_conv1/bias, block4_conv1/bias/Initializer/zeros)}}' was changed by setting attribute after it was run by a session. This mutation will have no effect, and will trigger an error in the future. Either don't modify nodes after running them or create a new session.
To implement gradient descent, we will need the gradient of this loss with respect to the model’s input. To do this, we will use the gradients function packaged with the backend module of Keras:
# The call to `gradients` returns a list of tensors (of size 1 in this case)# hence we only keep the first element -- which is a tensor.layer_output = model.get_layer(layer_name).outputloss = tf.keras.backend.mean(layer_output[:, :, :, filter_index])grads = K.gradients(loss, model.input)[0]
A non-obvious trick to use for the gradient descent process to go smoothly is to normalize the gradient tensor, by dividing it by its L2 norm (the square root of the average of the square of the values in the tensor). This ensures that the magnitude of the updates done to the input image is always within a same range.
# We add 1e-5 before dividing so as to avoid accidentally dividing by 0.grads /= (tf.keras.backend.sqrt(tf.keras.backend.mean(tf.keras.backend.square(grads))) +1e-5)
Now we need a way to compute the value of the loss tensor and the gradient tensor, given an input image. We can define a Keras backend function to do this: iterate is a function that takes a Numpy tensor (as a list of tensors of size 1) and returns a list of two Numpy tensors: the loss value and the gradient value.
iterate = K.function([model.input], [loss, grads])# Let's test it:import numpy as nploss_value, grads_value = iterate([np.zeros((1, 150, 150, 3))])
At this point we can define a Python loop to do stochastic gradient descent:
# We start from a gray image with some noiseinput_img_data = np.random.random((1, 150, 150, 3)) *20+128.# Run gradient ascent for 40 stepsstep =1.# this is the magnitude of each gradient updatefor i inrange(40):# Compute the loss value and gradient value loss_value, grads_value = iterate([input_img_data])# Here we adjust the input image in the direction that maximizes the loss input_img_data += grads_value * step
The resulting image tensor will be a floating point tensor of shape (1, 150, 150, 3), with values that may not be integer within [0, 255]. Hence we would need to post-process this tensor to turn it into a displayable image. We do it with the following straightforward utility function:
def deprocess_image(x):# normalize tensor: center on 0., ensure std is 0.1 x -= x.mean() x /= (x.std() +1e-5) x *=0.1# clip to [0, 1] x +=0.5 x = np.clip(x, 0, 1)# convert to RGB array x *=255 x = np.clip(x, 0, 255).astype('uint8')return x
Now we have all the pieces, let’s put them together into a Python function that takes as input a layer name and a filter index, and that returns a valid image tensor representing the pattern that maximizes the activation the specified filter:
def generate_pattern(layer_name, filter_index, size=150):# Build a loss function that maximizes the activation# of the nth filter of the layer considered. layer_output = model.get_layer(layer_name).output loss = K.mean(layer_output[:, :, :, filter_index])# Compute the gradient of the input picture wrt this loss grads = K.gradients(loss, model.input)[0]# Normalization trick: we normalize the gradient grads /= (K.sqrt(K.mean(K.square(grads))) +1e-5)# This function returns the loss and grads given the input picture iterate = K.function([model.input], [loss, grads])# We start from a gray image with some noise input_img_data = np.random.random((1, size, size, 3)) *20+128.# Run gradient ascent for 40 steps step =1.for i inrange(40): loss_value, grads_value = iterate([input_img_data]) input_img_data += grads_value * step img = input_img_data[0]return deprocess_image(img)
It seems that filter 0 in layer block3_conv1 is responsive to a polka dot pattern.
Now the fun part: we can start visualising every single filter in every layer. For simplicity, we will only look at the first 64 filters in each layer, and will only look at the first layer of each convolution block (block1_conv1, block2_conv1, block3_conv1, block4_conv1, block5_conv1). We will arrange the outputs on a 8x8 grid of 64x64 filter patterns, with some black margins between each filter pattern.
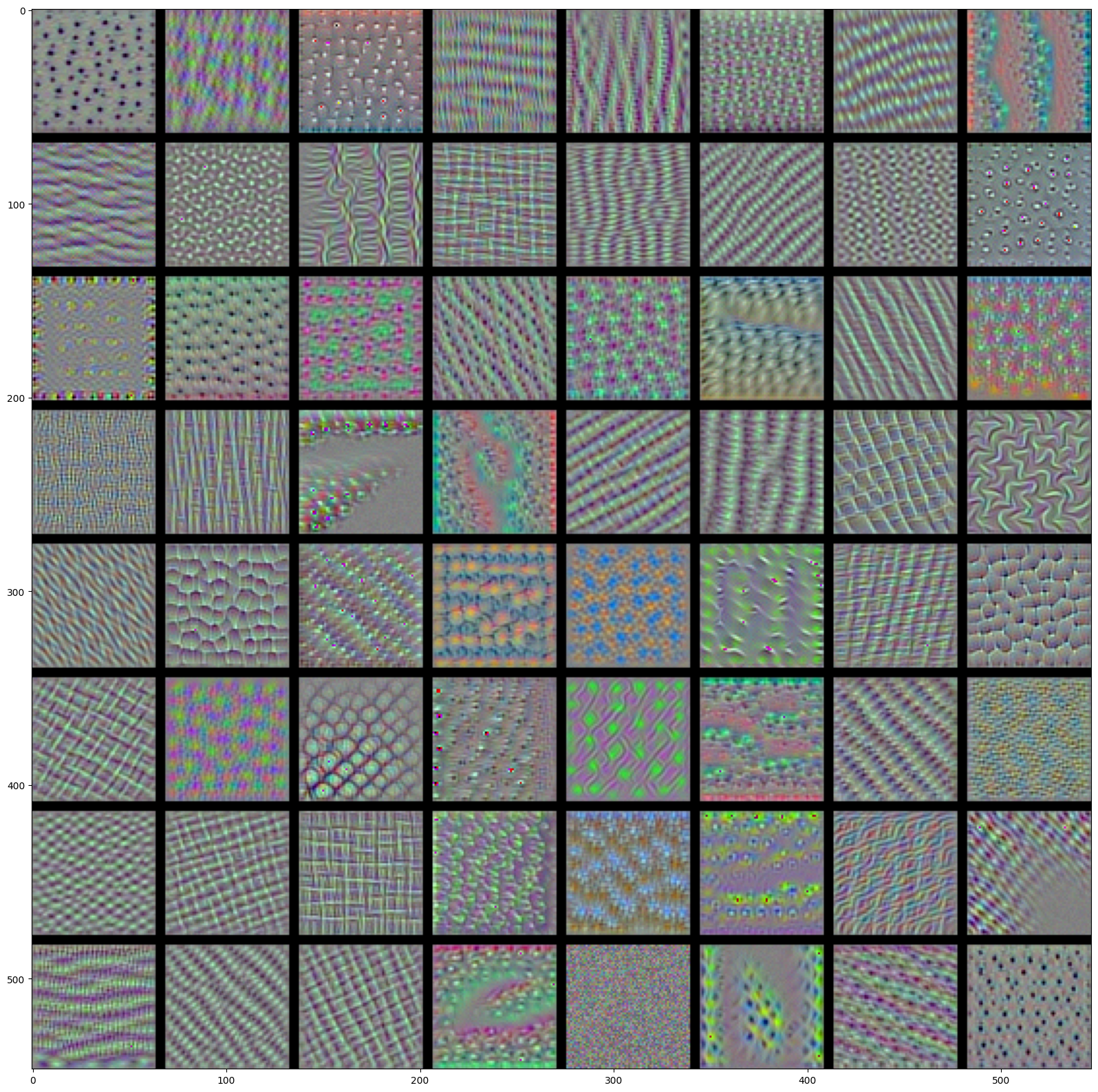
for layer_name in ['block1_conv1', 'block2_conv1', 'block3_conv1', 'block4_conv1']: size =64 margin =5# This a empty (black) image where we will store our results. results = np.zeros((8* size +7* margin, 8* size +7* margin, 3))for i inrange(8): # iterate over the rows of our results gridfor j inrange(8): # iterate over the columns of our results grid# Generate the pattern for filter `i + (j * 8)` in `layer_name` filter_img = generate_pattern(layer_name, i + (j *8), size=size)# Put the result in the square `(i, j)` of the results grid horizontal_start = i * size + i * margin horizontal_end = horizontal_start + size vertical_start = j * size + j * margin vertical_end = vertical_start + size results[horizontal_start: horizontal_end, vertical_start: vertical_end, :] = filter_img# Display the results grid plt.figure(figsize=(20, 20)) plt.imshow((results *255).astype(np.uint8)) plt.show()
These filter visualizations tell us a lot about how convnet layers see the world: each layer in a convnet simply learns a collection of filters such that their inputs can be expressed as a combination of the filters. This is similar to how the Fourier transform decomposes signals onto a bank of cosine functions. The filters in these convnet filter banks get increasingly complex and refined as we go higher-up in the model:
The filters from the first layer in the model (block1_conv1) encode simple directional edges and colors (or colored edges in some cases).
The filters from block2_conv1 encode simple textures made from combinations of edges and colors.
The filters in higher-up layers start resembling textures found in natural images: feathers, eyes, leaves, etc.
Visualizing heatmaps of class activation
We will introduce one more visualization technique, one that is useful for understanding which parts of a given image led a convnet to its final classification decision. This is helpful for “debugging” the decision process of a convnet, in particular in case of a classification mistake. It also allows you to locate specific objects in an image.
This general category of techniques is called “Class Activation Map” (CAM) visualization, and consists in producing heatmaps of “class activation” over input images. A “class activation” heatmap is a 2D grid of scores associated with an specific output class, computed for every location in any input image, indicating how important each location is with respect to the class considered. For instance, given a image fed into one of our “cat vs. dog” convnet, Class Activation Map visualization allows us to generate a heatmap for the class “cat”, indicating how cat-like different parts of the image are, and likewise for the class “dog”, indicating how dog-like differents parts of the image are.
The specific implementation we will use is the one described in Grad-CAM: Why did you say that? Visual Explanations from Deep Networks via Gradient-based Localization. It is very simple: it consists in taking the output feature map of a convolution layer given an input image, and weighing every channel in that feature map by the gradient of the class with respect to the channel. Intuitively, one way to understand this trick is that we are weighting a spatial map of “how intensely the input image activates different channels” by “how important each channel is with regard to the class”, resulting in a spatial map of “how intensely the input image activates the class”.
We will demonstrate this technique using the pre-trained VGG16 network again:
from keras.applications.vgg16 import VGG16K.clear_session()# Note that we are including the densely-connected classifier on top;# all previous times, we were discarding it.model = VGG16(weights='imagenet')
Downloading data from https://storage.googleapis.com/tensorflow/keras-applications/vgg16/vgg16_weights_tf_dim_ordering_tf_kernels.h5
50692096/553467096 [=>............................] - ETA: 5s553467096/553467096 [==============================] - 5s 0us/step
2023-10-12 14:56:58.439856: I tensorflow/compiler/xla/stream_executor/cuda/cuda_gpu_executor.cc:998] successful NUMA node read from SysFS had negative value (-1), but there must be at least one NUMA node, so returning NUMA node zero
2023-10-12 14:56:58.439989: I tensorflow/compiler/xla/stream_executor/cuda/cuda_gpu_executor.cc:998] successful NUMA node read from SysFS had negative value (-1), but there must be at least one NUMA node, so returning NUMA node zero
2023-10-12 14:56:58.440054: I tensorflow/compiler/xla/stream_executor/cuda/cuda_gpu_executor.cc:998] successful NUMA node read from SysFS had negative value (-1), but there must be at least one NUMA node, so returning NUMA node zero
2023-10-12 14:56:58.440150: I tensorflow/compiler/xla/stream_executor/cuda/cuda_gpu_executor.cc:998] successful NUMA node read from SysFS had negative value (-1), but there must be at least one NUMA node, so returning NUMA node zero
2023-10-12 14:56:58.440211: I tensorflow/compiler/xla/stream_executor/cuda/cuda_gpu_executor.cc:998] successful NUMA node read from SysFS had negative value (-1), but there must be at least one NUMA node, so returning NUMA node zero
2023-10-12 14:56:58.440266: I tensorflow/core/common_runtime/gpu/gpu_device.cc:1621] Created device /job:localhost/replica:0/task:0/device:GPU:0 with 1415 MB memory: -> device: 0, name: NVIDIA RTX A4500 Laptop GPU, pci bus id: 0000:01:00.0, compute capability: 8.6
2023-10-12 14:56:58.469183: W tensorflow/c/c_api.cc:291] Operation '{name:'block5_conv2/bias/Assign' id:290 op device:{requested: '', assigned: ''} def:{{{node block5_conv2/bias/Assign}} = AssignVariableOp[_has_manual_control_dependencies=true, dtype=DT_FLOAT, validate_shape=false](block5_conv2/bias, block5_conv2/bias/Initializer/zeros)}}' was changed by setting attribute after it was run by a session. This mutation will have no effect, and will trigger an error in the future. Either don't modify nodes after running them or create a new session.
Let’s consider the following image of two African elephants, possible a mother and its cub, strolling in the savanna (under a Creative Commons license):
elephants
Let’s convert this image into something the VGG16 model can read: the model was trained on images of size 224x244, preprocessed according to a few rules that are packaged in the utility function keras.applications.vgg16.preprocess_input. So we need to load the image, resize it to 224x224, convert it to a Numpy float32 tensor, and apply these pre-processing rules.
import numpy as np# The local path to our target image#img_path = 'creative_commons_elephant.jpg'img_path = tf.keras.utils.get_file( fname="elephant.jpg", origin="https://img-datasets.s3.amazonaws.com/elephant.jpg")# `img` is a PIL image of size 224x224img = tf.keras.utils.load_img(img_path, target_size=(224, 224))# `x` is a float32 Numpy array of shape (224, 224, 3)x = tf.keras.utils.img_to_array(img)# We add a dimension to transform our array into a "batch"# of size (1, 224, 224, 3)x = np.expand_dims(x, axis=0)# Finally we preprocess the batch# (this does channel-wise color normalization)x = tf.keras.applications.vgg16.preprocess_input(x)
Downloading data from https://img-datasets.s3.amazonaws.com/elephant.jpg
733657/733657 [==============================] - 1s 1us/step
Downloading data from https://storage.googleapis.com/download.tensorflow.org/data/imagenet_class_index.json
/usr/local/lib/python3.8/dist-packages/keras/engine/training_v1.py:2357: UserWarning: `Model.state_updates` will be removed in a future version. This property should not be used in TensorFlow 2.0, as `updates` are applied automatically.
updates=self.state_updates,
2023-10-12 14:57:01.338651: W tensorflow/c/c_api.cc:291] Operation '{name:'predictions/Softmax' id:401 op device:{requested: '', assigned: ''} def:{{{node predictions/Softmax}} = Softmax[T=DT_FLOAT, _has_manual_control_dependencies=true](predictions/BiasAdd)}}' was changed by setting attribute after it was run by a session. This mutation will have no effect, and will trigger an error in the future. Either don't modify nodes after running them or create a new session.
2023-10-12 14:57:01.447291: I tensorflow/compiler/xla/stream_executor/cuda/cuda_blas.cc:648] TensorFloat-32 will be used for the matrix multiplication. This will only be logged once.
Thus our network has recognized our image as containing an undetermined quantity of African elephants. The entry in the prediction vector that was maximally activated is the one corresponding to the “African elephant” class, at index 386:
np.argmax(preds[0])
386
To visualize which parts of our image were the most “African elephant”-like, let’s set up the Grad-CAM process:
# This is the "african elephant" entry in the prediction vectorafrican_elephant_output = model.output[:, 386]# The is the output feature map of the `block5_conv3` layer,# the last convolutional layer in VGG16last_conv_layer = model.get_layer('block5_conv3')# This is the gradient of the "african elephant" class with regard to# the output feature map of `block5_conv3`grads = K.gradients(african_elephant_output, last_conv_layer.output)[0]# This is a vector of shape (512,), where each entry# is the mean intensity of the gradient over a specific feature map channelpooled_grads = K.mean(grads, axis=(0, 1, 2))# This function allows us to access the values of the quantities we just defined:# `pooled_grads` and the output feature map of `block5_conv3`,# given a sample imageiterate = K.function([model.input], [pooled_grads, last_conv_layer.output[0]])# These are the values of these two quantities, as Numpy arrays,# given our sample image of two elephantspooled_grads_value, conv_layer_output_value = iterate([x])# We multiply each channel in the feature map array# by "how important this channel is" with regard to the elephant classfor i inrange(512): conv_layer_output_value[:, :, i] *= pooled_grads_value[i]# The channel-wise mean of the resulting feature map# is our heatmap of class activationheatmap = np.mean(conv_layer_output_value, axis=-1)
For visualization purpose, we will also normalize the heatmap between 0 and 1:
Finally, we will use OpenCV to generate an image that superimposes the original image with the heatmap we just obtained:
import cv2# We use cv2 to load the original imageimg = cv2.imread(img_path)# We resize the heatmap to have the same size as the original imageheatmap = cv2.resize(heatmap, (img.shape[1], img.shape[0]))# We convert the heatmap to RGBheatmap = np.uint8(255* heatmap)# We apply the heatmap to the original imageheatmap = cv2.applyColorMap(heatmap, cv2.COLORMAP_JET)# 0.4 here is a heatmap intensity factorsuperimposed_img = heatmap *0.4+ img# Save the image to diskcv2.imwrite('images/elephant_cam.jpg', superimposed_img)
---------------------------------------------------------------------------ModuleNotFoundError Traceback (most recent call last)
/workspaces/artificial_intelligence/artificial_intelligence/aiml-common/lectures/cnn/cnn-example-architectures/visualizing-what-convnets-learn.ipynb Cell 55 line 1
----> <a href='vscode-notebook-cell://dev-container%2B7b22686f737450617468223a222f686f6d652f70616e74656c69732e6d6f6e6f67696f756469732f6c6f63616c2f7765622f73697465732f636f75727365732f6172746966696369616c5f696e74656c6c6967656e6365222c226c6f63616c446f636b6572223a66616c73652c2273657474696e6773223a7b22686f7374223a22756e69783a2f2f2f7661722f72756e2f646f636b65722e736f636b227d2c22636f6e66696746696c65223a7b22246d6964223a312c22667350617468223a222f686f6d652f70616e74656c69732e6d6f6e6f67696f756469732f6c6f63616c2f7765622f73697465732f636f75727365732f6172746966696369616c5f696e74656c6c6967656e63652f2e646576636f6e7461696e65722f646576636f6e7461696e65722e6a736f6e222c2265787465726e616c223a2266696c653a2f2f2f686f6d652f70616e74656c69732e6d6f6e6f67696f756469732f6c6f63616c2f7765622f73697465732f636f75727365732f6172746966696369616c5f696e74656c6c6967656e63652f2e646576636f6e7461696e65722f646576636f6e7461696e65722e6a736f6e222c2270617468223a222f686f6d652f70616e74656c69732e6d6f6e6f67696f756469732f6c6f63616c2f7765622f73697465732f636f75727365732f6172746966696369616c5f696e74656c6c6967656e63652f2e646576636f6e7461696e65722f646576636f6e7461696e65722e6a736f6e222c22736368656d65223a2266696c65227d7d/workspaces/artificial_intelligence/artificial_intelligence/aiml-common/lectures/cnn/cnn-example-architectures/visualizing-what-convnets-learn.ipynb#Y105sdnNjb2RlLXJlbW90ZQ%3D%3D?line=0'>1</a> import cv2
<a href='vscode-notebook-cell://dev-container%2B7b22686f737450617468223a222f686f6d652f70616e74656c69732e6d6f6e6f67696f756469732f6c6f63616c2f7765622f73697465732f636f75727365732f6172746966696369616c5f696e74656c6c6967656e6365222c226c6f63616c446f636b6572223a66616c73652c2273657474696e6773223a7b22686f7374223a22756e69783a2f2f2f7661722f72756e2f646f636b65722e736f636b227d2c22636f6e66696746696c65223a7b22246d6964223a312c22667350617468223a222f686f6d652f70616e74656c69732e6d6f6e6f67696f756469732f6c6f63616c2f7765622f73697465732f636f75727365732f6172746966696369616c5f696e74656c6c6967656e63652f2e646576636f6e7461696e65722f646576636f6e7461696e65722e6a736f6e222c2265787465726e616c223a2266696c653a2f2f2f686f6d652f70616e74656c69732e6d6f6e6f67696f756469732f6c6f63616c2f7765622f73697465732f636f75727365732f6172746966696369616c5f696e74656c6c6967656e63652f2e646576636f6e7461696e65722f646576636f6e7461696e65722e6a736f6e222c2270617468223a222f686f6d652f70616e74656c69732e6d6f6e6f67696f756469732f6c6f63616c2f7765622f73697465732f636f75727365732f6172746966696369616c5f696e74656c6c6967656e63652f2e646576636f6e7461696e65722f646576636f6e7461696e65722e6a736f6e222c22736368656d65223a2266696c65227d7d/workspaces/artificial_intelligence/artificial_intelligence/aiml-common/lectures/cnn/cnn-example-architectures/visualizing-what-convnets-learn.ipynb#Y105sdnNjb2RlLXJlbW90ZQ%3D%3D?line=2'>3</a> # We use cv2 to load the original image
<a href='vscode-notebook-cell://dev-container%2B7b22686f737450617468223a222f686f6d652f70616e74656c69732e6d6f6e6f67696f756469732f6c6f63616c2f7765622f73697465732f636f75727365732f6172746966696369616c5f696e74656c6c6967656e6365222c226c6f63616c446f636b6572223a66616c73652c2273657474696e6773223a7b22686f7374223a22756e69783a2f2f2f7661722f72756e2f646f636b65722e736f636b227d2c22636f6e66696746696c65223a7b22246d6964223a312c22667350617468223a222f686f6d652f70616e74656c69732e6d6f6e6f67696f756469732f6c6f63616c2f7765622f73697465732f636f75727365732f6172746966696369616c5f696e74656c6c6967656e63652f2e646576636f6e7461696e65722f646576636f6e7461696e65722e6a736f6e222c2265787465726e616c223a2266696c653a2f2f2f686f6d652f70616e74656c69732e6d6f6e6f67696f756469732f6c6f63616c2f7765622f73697465732f636f75727365732f6172746966696369616c5f696e74656c6c6967656e63652f2e646576636f6e7461696e65722f646576636f6e7461696e65722e6a736f6e222c2270617468223a222f686f6d652f70616e74656c69732e6d6f6e6f67696f756469732f6c6f63616c2f7765622f73697465732f636f75727365732f6172746966696369616c5f696e74656c6c6967656e63652f2e646576636f6e7461696e65722f646576636f6e7461696e65722e6a736f6e222c22736368656d65223a2266696c65227d7d/workspaces/artificial_intelligence/artificial_intelligence/aiml-common/lectures/cnn/cnn-example-architectures/visualizing-what-convnets-learn.ipynb#Y105sdnNjb2RlLXJlbW90ZQ%3D%3D?line=3'>4</a> img = cv2.imread(img_path)
ModuleNotFoundError: No module named 'cv2'
elephant cam
This visualisation technique answers two important questions:
Why did the network think this image contained an African elephant?
Where is the African elephant located in the picture?
In particular, it is interesting to note that the ears of the elephant cub are strongly activated: this is probably how the network can tell the difference between African and Indian elephants.