Introduction to Convolutional Neural Networks
The Convolution & Cross-Correlation Operation
The key operation performed in CNN layers is that of 2D convolution. In fact in practice they are 4D convolutions as we try to learn many filters and we also consider many input images (mini-batch) in the iteration of our SGD optimizer.
We cover first the 1-dimensional case.
1D Convolution
By definition the convolution between two functions in one dimension is given by:
\[(a * b)[n] = \sum_{m=-\inf}^{\inf} a[m]b[n-m]\]
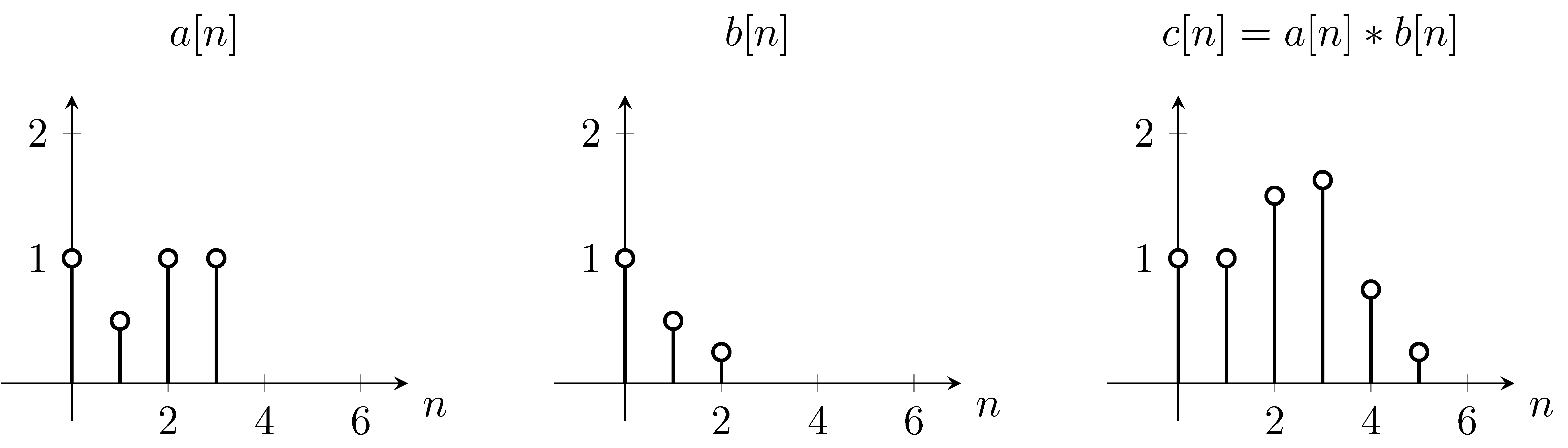 1D-convolution example. The operation effectively slides the flipped version of \(b\) across \(a\)
1D-convolution example. The operation effectively slides the flipped version of \(b\) across \(a\)
The result can be calculated as follows:
\(c[0] = \sum_m a[m]b[-m] = 0 * 0.25 + 0 * 0.5 + 1 * 1 + 0.5 * 0 + 1 * 0 + 1 * 0 = 1\)
\(c[1] = \sum_m a[m]b[1-m] = 0 * 0.25 + 1 * 0.5 + 0.5 * 1 + 1 * 0 + 1 * 0 = 1\)
\(c[2] = \sum_m a[m]b[2-m] = 1 * 0.25 + 0.5 * 0.5 + 1 * 1 + 1 * 0 + 1 * 0 = 1.5\)
\(c[3] = \sum_m a[m]b[3-m] = 1 * 0 + 0.5 * 0.25 + 1 * 0.5 + 1 * 1 = 1.625\)
and so on.
Convolution and cross-correlation are very close - see this 1D example (source to persuade yourself that this is the case.
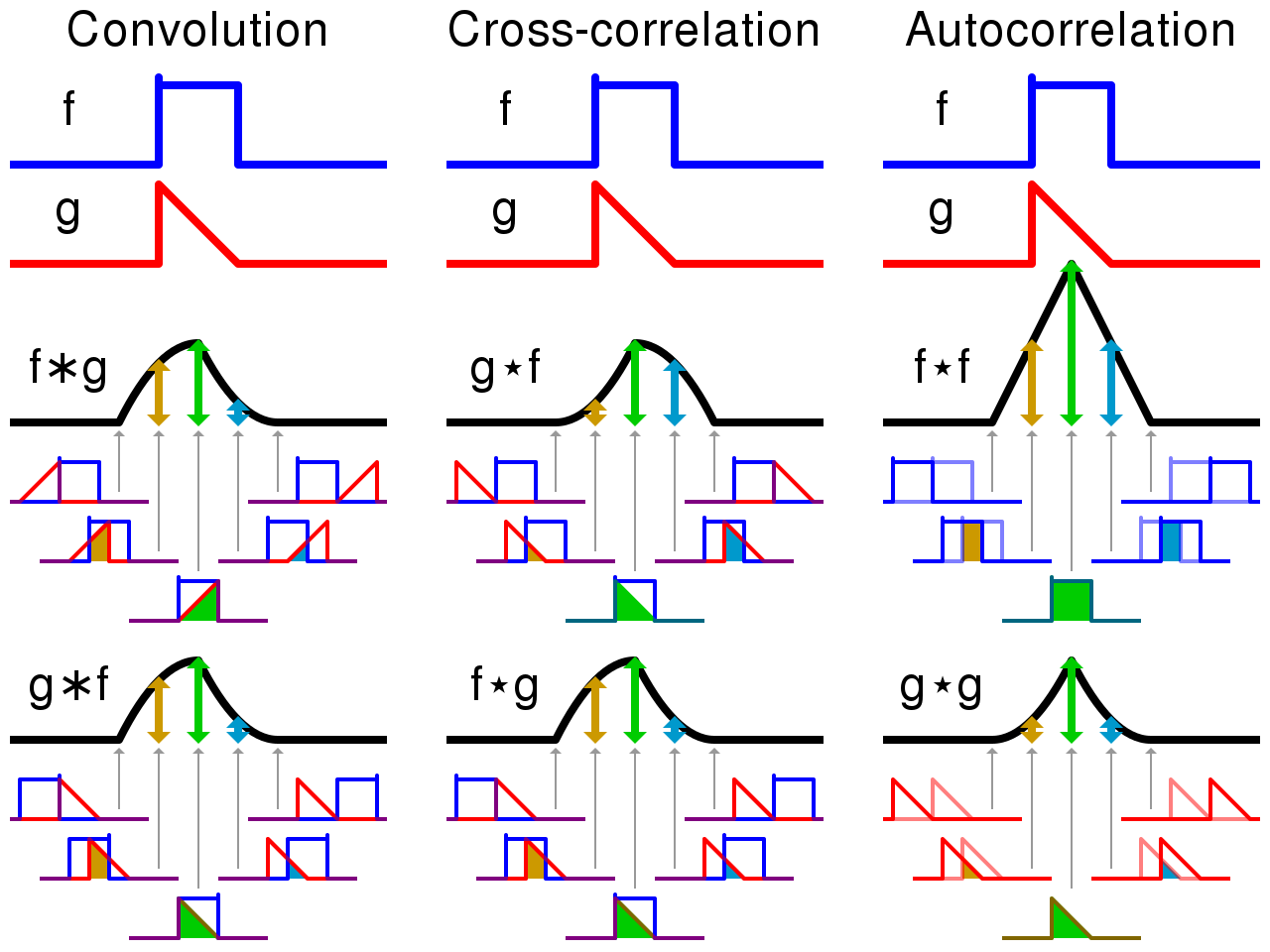 Convolution and cross-correlation are very similar quantities
Convolution and cross-correlation are very similar quantities
2D Convolution
In 2D the same principle applies. First, the convolution operation in some frameworks is the flipped version - this is perfectly fine as the convolution operation is commutative.
\[S(i,j) = \sum_m \sum_n x(m, n) h(i-m,j-n) = \sum_m \sum_n x(i-m, j-n)h(m,n)\]
where \(x\) is the input of the convolution and \(h\) is the kernel or filter typically of smaller spatial dimensions.
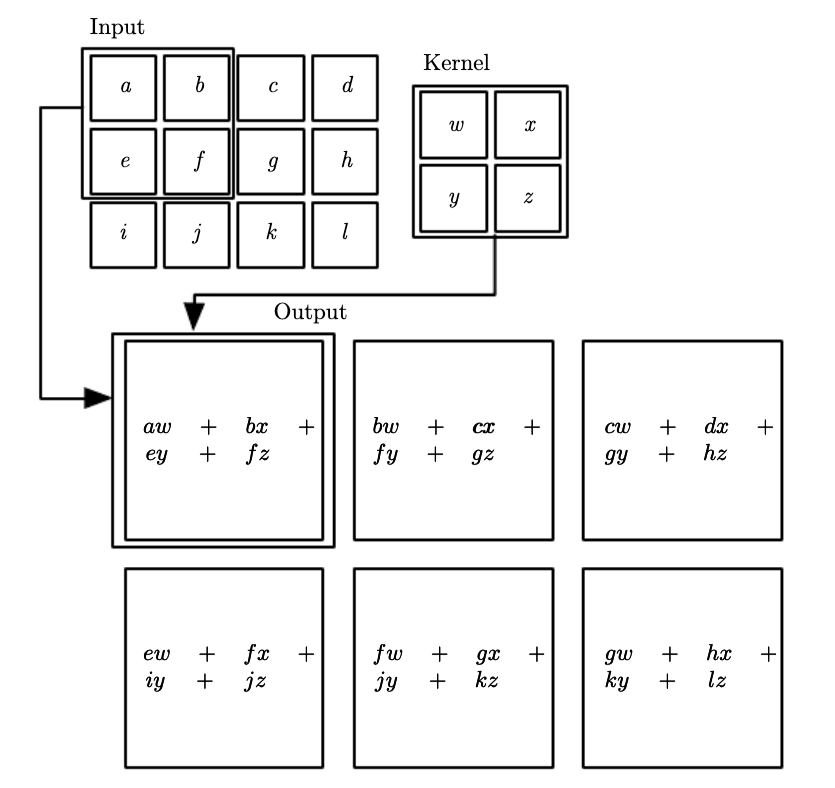
Many ML frameworks don’t even implemented convolution but they do the very similar cross-correlation operation and they sometimes call it convolution to add to the confusion. Tensorflow implements the cross-correlation operation under the hood.
\[S(i,j) = \sum_u \sum_v x(i+u, j+v)h(u,v)\]
If you learn the flipped version of the kernel or not is irrelevant to the task of predicting the right label. Therefore you should not be concerned with the framework implementation details, the thing that is important for you to grasp is the essence of the operation. Lets look some effects that convolution has on input signals such as images.
Effects of 2D filtering operations
Moving Average
Lets go through the simplest possible 2D filtering operation as shown below. Note that these implement the convolution.
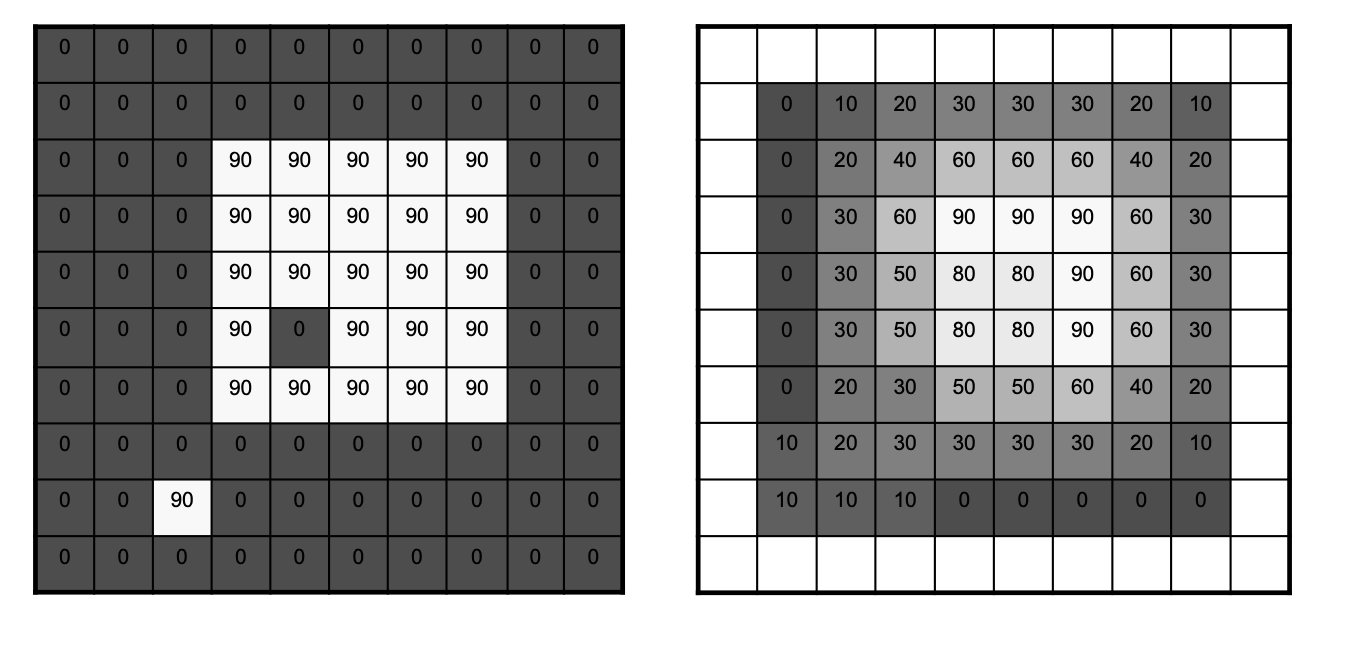 Completed 2D MA Filtering
Completed 2D MA Filtering
 The MA filter causes “box” blurring of input images
The MA filter causes “box” blurring of input images
2D Gaussian
Using a Gaussian Blur filter before edge detection aims to reduce the level of noise in the image, which improves the result of the susually subsequent edge-detection algorithms. We will meet again this 2D Gaussian filter in the object detection section, where it is used to help in the initial segmentation in RCNN architectures.
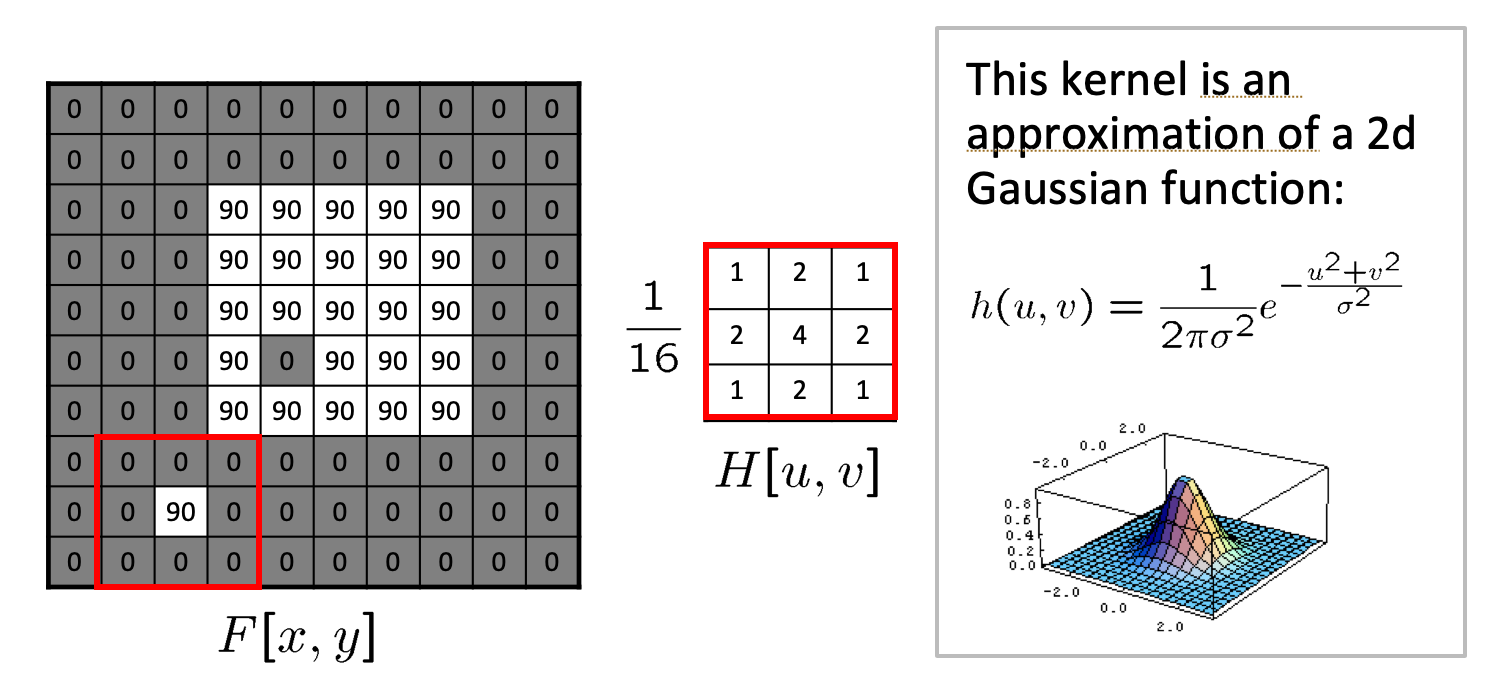 Gaussian Filter
Gaussian Filter
 Blurring is evident in this picture
Blurring is evident in this picture
 Blurring is used to improve edge-detection
Blurring is used to improve edge-detection
The above filtering operations are obviously deterministic. We are given the filter but in CNNs as we will see in the next section we are learning such filters. To keep the terminology aligned with the dense neural networks layers we will be denoting the filter with \(\mathbf w\) - the weights that need to be learned through the training process.