Word2Vec Embeddings
Introduction
In the so called classical NLP, words were treated as atomic symbols, e.g. hotel, conference, walk and they were represented with on-hot encoded (sparse) vectors e.g.
\[\mathtt{hotel} = [0,0, ..., 0,1, 0,0,..,0]\] \[\mathtt{motel} = [0,0, ..., 0,0, 0,1,..,0]\]
The size of the vectors is equal to the vocabulary size \(V\). These vocabularies are very long - for speech recognition we may be looking at 20K entries but for information retrieval on the web google has released vocabularies with 13 million words (1TB). In addition such representations are orthogonal to each other by construction - there is no way we can relate motel and hotel as their dot product is
\[ s = \mathtt{hotel}^T \mathtt{motel} = 0.0\]
One of key ideas that made NLP successful is the distributional semantics that originated from Firth’s work: a word’s meaning is given by the words that frequently appear close-by. When a word \(x\) appears in a text, its context is the set of words that appear nearby (within a fixed-size window). Use the many contexts of \(x\) to build up a representation of \(x\).
 Distributional similarity representations -
Distributional similarity representations - banking is represented by the words left and right across all sentences of our corpus.
This is the main idea behind word2vec word embeddings (representations) that we address next.
Before we deal with embeddings though its important to address a conceptual question:
Is there some ideal word-embedding space that would perfectly map human language and could be used for any natural-language-processing task? Possibly, but we have yet to compute anything of the sort. More pragmatically, what makes a good word-embedding space depends heavily on your task: the perfect word-embedding space for an English-language movie-review sentiment-analysis model may look different from the perfect embedding space for an English-language legal–document-classification model, because the importance of certain semantic relationships varies from task to task. It’s thus reasonable to learn a new embedding space with every new task.
Features of Word2Vec embeddings
In 2012, Thomas Mikolov, an intern at Microsoft, found a way to encode the meaning of words in a modest number of vector dimensions \(d\). Mikolov trained a neural network to predict word occurrences near each target word. In 2013, once at Google, Mikolov and his teammates released the software for creating these word vectors and called it word2vec.
 word2vec generated embedding for the word
word2vec generated embedding for the word banking in d=8 dimensions
Here is a visualization of these embeddings in the re-projected 3D space (from \(d\) to 3). Try searching for the word “truck” for the visualizer to show the distorted neighbors of this work - distorted because of the 3D re-projection. In another example, word2vec embeddings of US cities projected in the 2D space result in poor topological but excellent semantic mapping which is exactly what we are after.
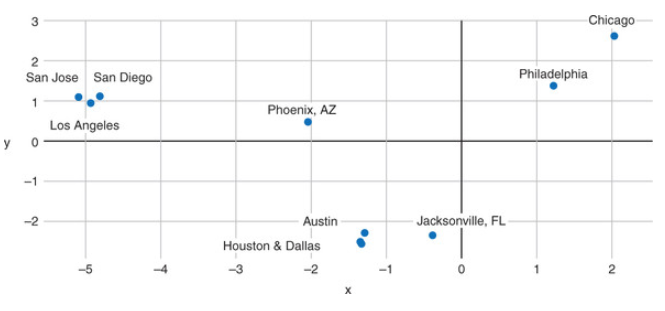 Semantic Map produced by word2vec for US cities
Semantic Map produced by word2vec for US cities
Another classic example that shows the power of word2vec representations to encode analogies, is classical king + woman − man ≈ queen example shown below.
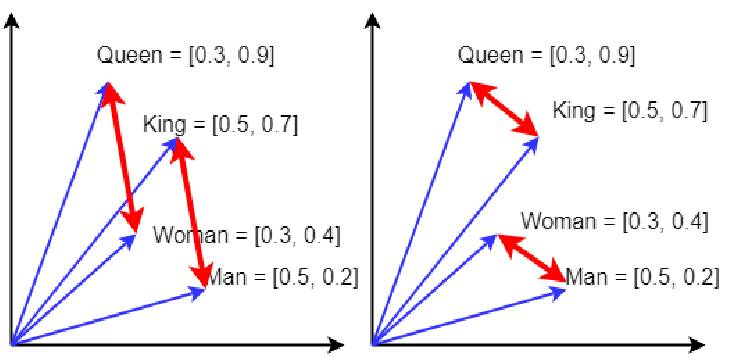 Classic queen example where
Classic queen example where king − man ≈ queen − woman, and we can visually see that in the red arrows. There are 4 analogies one can construct, based on the parallel red arrows and their direction. This is slightly idealized; the vectors need not be so similar to be the most similar from all word vectors. The similar direction of the red arrows indicates similar relational meaning.
So what is the more formal description of the word2vec algorithm? We will focus on one of the two computational algorithms1 - the skip-gram method and use the following diagrams as examples to explain how it works.
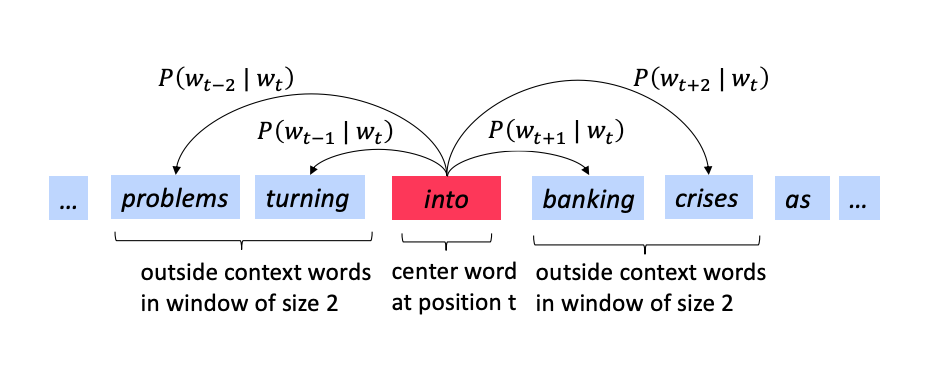
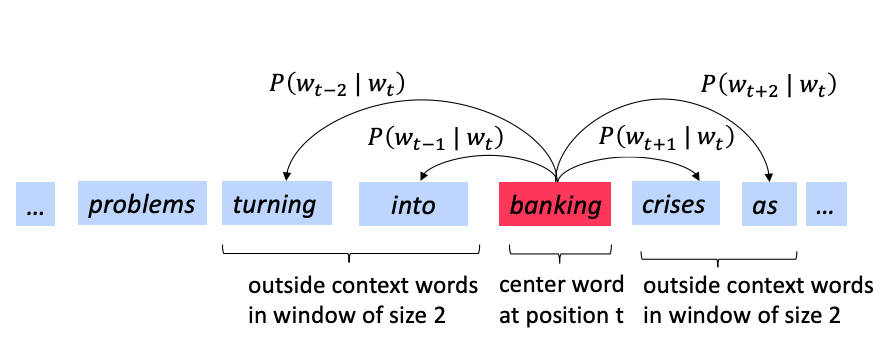 In the skip-gram we predict the context given the center word.We need to calculate the probability \(p(w_{t+j} | w_t)\).
In the skip-gram we predict the context given the center word.We need to calculate the probability \(p(w_{t+j} | w_t)\).
We go through each position \(t\) in each sentence and for the center word at that location \(w_t\) we predict the outside words \(w_{t+j}\) where \(j\) is over a window of size \(C = |\{ j: -m \le j \le m \}|-1\) around \(w_t\).
For example, the meaning of banking is predicting the context (the words around it) in which banking occurs across our corpus.
The term prediction points to the regression section and the maximum likelihood principle. We start from the familiar cross entropy loss and architect a neural estimator that will minimize the distance between \(\hat p_{data}\) and \(p_{model}\). The negative log likelihood was shown to be:
\[J(\theta) = -\frac{1}{V} \log L(\theta) = -\frac{1}{V} \sum_{t=1}^V \sum_{-m\le j \le m, j \neq 0} \log p(w_{t+j} | w_t; \theta)\]
where \(|V|\) is the size of the vocabulary (words).\(|V|\) could be very large, e.g. 1 billion words. The ML principle, powered by a corresponding algorithm, will result in a model that for each word at the input (center) will predict the context words around it. The model parameters \(\theta\) will be determined at the end of the training process that uses a training dataset easily generated from our corpus assuming we fix the context window \(m\). Lets see an example:
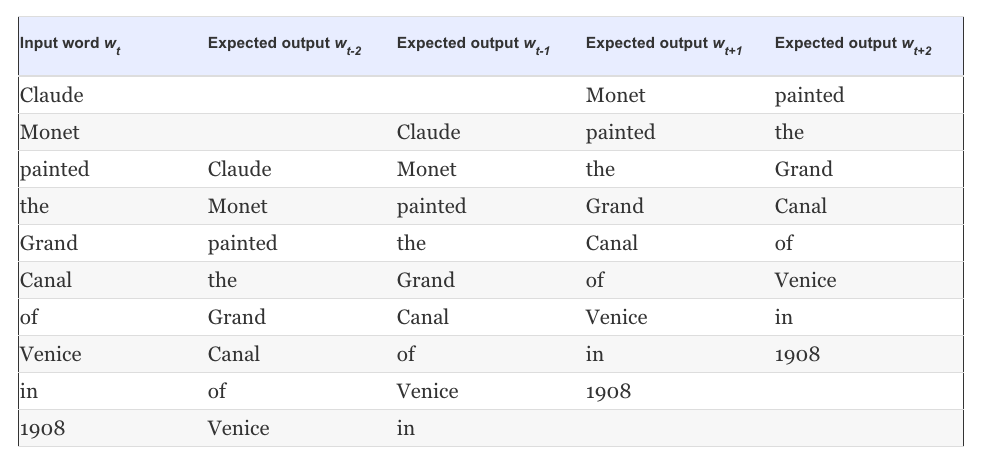 Training data generation for the sentence ‘Claude Monet painted the Grand Canal of Venice in 1908’
Training data generation for the sentence ‘Claude Monet painted the Grand Canal of Venice in 1908’
So the question now becomes how to calculate \(p(w_{t+j} | w_t; \theta)\) and we do so with the network architecture below.
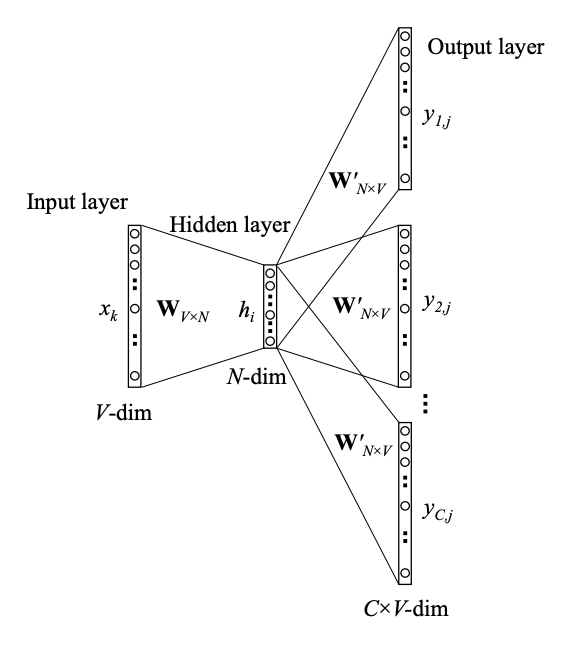 Conceptual architecture of the neural network that learns word2vec embeddings. The text refers to the hidden layer dimensions as \(d\) rather than \(N\) and hidden layer \(\mathbf z\) rather than \(\mathbf h\).
Conceptual architecture of the neural network that learns word2vec embeddings. The text refers to the hidden layer dimensions as \(d\) rather than \(N\) and hidden layer \(\mathbf z\) rather than \(\mathbf h\).
The network accepts the center word and via an embedding layer \(\mathbf W_{|V| \times d}\) produces a hidden layer \(\mathbf z\). The same hidden layer output is then mapped to an output layer of size \(C \times |V|\), via \(\mathbf W^\prime_{d \times |V|}\). One mapping is done for each of the words that we include in the context. In the output layer we then convert the metrics \(\mathbf z^\prime\) to a probability distribution \(\hat{\mathbf y}\) via the softmax. This is summarized next:
\[\mathbf z = \mathbf x^T \mathbf W\] \[\mathbf z^\prime_j = \mathbf z \mathbf W^\prime_j, j \in [1,...,C]\] \[\hat{\mathbf y}_j = \mathtt{softmax}(\mathbf z^\prime_j), j \in [1,...,C]\] \[L = CE(\mathbf{y}, \hat{\mathbf y} )\]
The parameters \[ \theta = \{\mathbf W, \mathbf W^{\prime} \} \] will be optimized via an optimization algorithm (from the usual SGD family).
Training for large vocabularies can be quite computationally intensive. At the end of training we are then able to store the matrix \(\mathbf W\) and load it during the parsing stage of the NLP pipeline. In practice we use a loss functions that avoids computing losses that go over the vocabulary size \(|V|\) and instead we pose the problem as a logistic regression problem where the positive examples are the (center,context) word pairs and the negative examples are the (center, random) word pairs. This is called negative sampling and the interested reader can read more here.
Mind the important difference between learning a representation that from the context across the corpus and the application of that representation. Word2Vec are applied context-free. After training, a single \(\mathbf W\) matrix will be used. This means that the word ‘bank’ will be encoded using the same dense vector irrespectively when it is located close to ‘river’ or ‘food’ or ‘deposit’.
Contextual representations will be addressed in a separate section.
Example
Consider the training corpus having the following sentences:
“the dog saw a cat”,
“the dog chased the cat”,
“the cat climbed a tree”
In this corpus \(V=8\) and we are interested in creating word embeddings of order \(d=3\). The parameter matrices are randomly initialized as
\[W = \begin{bmatrix} 0.54 & 0.28 & 0.42\\0.84 & 0.00 & 0.12\\ 0.67 & 0.83 & 0.14\\0.58 & 0.89 & 0.21\\0.19 & 0.11 & 0.22\\0.98 & 0.81 & 0.17\\0.82 & 0.27 & 0.43\\0.94 & 0.82 & 0.34 \end{bmatrix}\]
\[ W^\prime = \begin{bmatrix}0.18 & 0.37 & 0.01 & 0.25 & 0.80 & 0.02 & 0.60 & 0.60\\0.11 & 0.38 & 0.04 & 0.89 & 0.98 & 0.06 & 0.89 & 0.58\\0.74 & 0.63 & 0.58 & 0.02 & 0.21 & 0.54 & 0.77 & 0.25 \end{bmatrix}\]
Suppose we want the network to learn relationship between the words “cat” and “climbed”. That is, the network should show a high probability for “cat” when “climbed” is presented at the input of the network. In word embedding terminology, the word “cat” is referred as the target word and the word “climbed” is referred as the context word. In this case, the input vector \(\mathbf x_{t+1} = [0 0 0 1 0 0 0 0]^T\). Notice that only the 4th component of the vector is 1 - the input word “climbed” holds for example the 4th position in a sorted list of corpus words. Given that the target word is “cat”, the target vector will be \(\mathbf x_t = [0 1 0 0 0 0 0 0 ]^T\).
With the input vector representing “climbed”, the output at the hidden layer neurons can be computed as
\[\mathbf z_t^T = \mathbf x_{t+j}^T \mathbf W = \begin{bmatrix} 0.58 & 0.89 & 0.21 \end{bmatrix}, j=1\]
Carrying out similar manipulations for hidden to output layer, the activation vector for output layer neurons can be written as
\[\mathbf z^\prime_j = \mathbf z_t^T \mathbf W^\prime =\begin{bmatrix} 0.35 & 0.69 & 0.16 & 0.94 & 1.38 & 0.18 & 1.30 & 0.91 \end{bmatrix}\]
Since the goal is produce probabilities for words in the output layer, \(p(w_{t+j} | w_t; \theta)\) to reflect their next word relationship with the context word at input, we need the sum of neuron outputs in the output layer to add to one. This can be achieved with the softmax
\[\hat{\mathbf y}_j = \mathtt{softmax}(\mathbf z^\prime_j), j=1\]
Thus, the probabilities for eight words in the corpus are:
\[\hat{\mathbf y} = \begin{bmatrix} 0.35 & \mathbf{0.69} & 0.16 & 0.94 & 1.38 & 0.18 & 1.30 & 0.91 \end{bmatrix}\]
The probability in bold is for the chosen target word ‘cat’. Given the target vector [0 1 0 0 0 0 0 0 ], the error vector for the output layer is easily computed via CE loss. Once the loss is known, the weights in the matrices W can be updated using backpropagation. Thus, the training can proceed by presenting different context-target words pairs from the corpus. The context can be more than one word and in this case the loss is the average loss across all pairs.
References
The simple example was from here.