We start by reviewing the agent-environment interface with this evolved notation and provide additional definitions that will help in grasping the concepts behind DRL. We treat MDP analytically effectively deriving the four Bellman equations.
Agent-Environment Interface
The following table summarizes the notation and contains useful definitions that we will use to describe required concepts later. With capital letters we denote the random variables involved and with small letters their specific realizations (values) - for example \(S_t\) is the random state variable and \(s_t\) is the actual state at time \(t\).
Symbol
Description
\(S_t\)
environment state at time step \(t\), \(s \in \mathcal{S}\) the finite set of states
\(A_t\)
agent action at time step \(t\), \(a \in \mathcal{A}\) the finite set of actions
\(R_{t+1} \in \mathbb{R}\)
numerical reward sent by the environment after taking action \(A_t\) and transition to next state \(S_{t+1}=s'\)
\(t\)
time step index associated with each experience that is defined as the tuple (\(S_t, A_t, R_{t+1}\)).
\(T\)
final time step beyond which the interaction terminates
episode
the time horizon from \(t=0\) to \(T-1\)
\(\tau\)
trajectory - the sequence of experiences over an episode
\(G_t\)
return - the total discounted rewards from time step \(t\) - it will be qualified shortly.
\(\gamma\)
the discount factor \(\gamma \in [0,1]\) embedded into the return \(G_t\)
In fully observed MDP problems, the agent perceives fully the environment state \(S_t\) - you can assume that there is a bank of sensors but they are ideal. In other words the agent knows which state the environment is in, perfectly.
A Note on the state definition of the MDP problem
Note that Markov processes are sometimes erroneously called memoryless but in any MDP above we can incorporate memory aka dependence in more than one state over time by cleverly defining the state \(S_t\) as a container of a number of states. For example, \(S_t = \left[ S_t=s, S_{t-1} = s^\prime \right]\) can still define an Markov transition using \(S\) states. The transition model
DeepMind’s Q-learning algorithm playing pac-man converts the non-MDP problem to MDP by accumulating four frames instead of one. With a single frame the problem was not MDP since the state of all players could not be known - with a single frame the pacman could not know if the monster was moving towards it or nor for example. With a number of frames we get to know all the information needed to act optimally on this game.
MDP Loop
We define a Markov Decision Process as the 5-tuple \(\mathcal M = <\mathcal S, \mathcal P, \mathcal R, \mathcal A, \gamma>\) that produces a sequence of experiences \((S_t, A_t, R_{t+1}), (S_{t+1}, A_{t+1}, R_{t+2}), ...\). The MDP (event) loop is shown below:
This generic interface between the agent and the environment captures many problems outside of pure MDP including RL. The environment’s state in non-MDP problems can be experienced via sensor observations and the agent will build its own state estimate internally
At the beginning of each episode, the environment and the agent are reset (lines 3–4). On reset, the environment produces an initial state. Then they begin interacting—an agent produces an action given a state (line 6), then the environment produces the next state and reward given the action (line 7), stepping into the next time step. The agent.act-env.step cycle continues until the maximum time step \(T\) is reached or the environment terminates. Here we also see a new component, agent.update (line 8), which encapsulates an agent’s learning algorithm. Over multiple time steps and episodes, this method collects data and performs learning internally to maximize the objective.
We can now instantiate an simple environment in Gymnasium:
%matplotlib inlineimport gymnasium as gymimport pandas as pdenv = gym.make("LunarLander-v2", render_mode="rgb_array")observation, info = env.reset(seed=0)# Create an empty dataframe with the desired columnsdf = pd.DataFrame( columns=['Action', 'Observation', 'Reward'] )dfs = [] for _ inrange(1000): action = env.action_space.sample() # agent policy that uses the observation and info observation, reward, terminated, truncated, info = env.step(action)# Append the data to the dataframe row_df = pd.DataFrame({'Action': action, 'Observation': observation, 'Reward': reward}) dfs.append(row_df)if terminated or truncated: observation, info = env.reset()df = pd.concat(dfs, ignore_index=True)print(df.tail())env.close()
The docker container as of May 2023 seems to have a problem with the gymnaisum package in certain environments. Sometimes the kernel in vscode will crash - we will investigate this further when we rewrite these MDP pages during the summer of 2023 to make them more interactive.
The MDP dynamics
The four foundational ingredients of MDP are:
Policy,
Reward,
Value function and
Model of the environment.
These are obtained from the dynamics of the finite MDP random process.
\[p(s', r | s , a) = \Pr\{ S_{t+1} = s', R_{t+1} = r | S_{t}=s, A_{t}=a \}\]
where \(s^\prime\) simply translates in English to the successor state whatever the new state is.
The dynamics probability density function maps \(\mathcal{S} \times \mathcal{R} \times \mathcal{S} \times \mathcal{A} \rightarrow [0,1]\) and by marginalizing over the appropriate random variables we can get the probability distributions and statistical quantities.
State transition
The action that the agent takes change the environment state to some other state. This can be represented via the environment state transition probabilistic model that generically can be written as:
\[ p(s'|s,a) = p[S_{t+1}=s^\prime | S_t=s, A_t=a ] = \sum_{r \in \mathcal{R}} p(s', r | s , a)\]
This function can be represented as a state transition probability tensor \(\mathcal P\)
where one dimension represents the action space and the other two constitute a state transition probability matrix.
Reward function
The action will also cause the environment to send the agent a signal called instantaneous reward\(R_{t+1}\). The reward signal is effectively defining the goal of the agent and is the primary basis for altering a policy. The agent’s sole objective is to maximize the cumulative reward in the long run.
Note
Please note that in the literature the reward is also denoted as \(R_{t}\) - this is a convention issue rather than something fundamental. The justification of the index \(t+1\) is that the environment will take one step to respond to what action the agent took.
The instantaneous reward is obtained by executing the reward function. the There are two broad cases for defining the reward function:
It can be a function of just the current state and the action we just committed to take and it is written as \(r(s,a)\).
It can include the current state, the action and next state and it is writen as \(r(s,a,s^\prime)\)
Here is an example of for the Lunar Lander environment.
import gymenv = gym.make('LunarLander-v2')def reward_function(state, action, next_state):# Unpack the state and action x, y, v_x, v_y, angle, v_angle, left_leg, right_leg = state a, t = action# Unpack the next state next_x, next_y, next_v_x, next_v_y, next_angle, next_v_angle, next_left_leg, next_right_leg = next_state# Compute the reward based on the next state reward =0# Negative reward for crashingif next_y <=0: reward -=100# Positive reward for landing successfullyif next_y >0andabs(next_angle) <0.1andabs(next_v_x) <0.2andabs(next_v_y) <0.2: reward +=100# Negative reward for running out of fuelif next_left_leg <0.01or next_right_leg <0.01: reward -=10# Penalty for using the engine reward -=abs(a) *0.1return reward
Please note that the instantaneus reward may be stochastic. This is a very important point and as an example consider the multi-armed bandit problems. The reward function there returns a random value based on the arm selected by the agent as shown. Dont be fooled by considering that multi-armed bandits apply to the cazino slot machines only. The multi-armed bandit problem applied far more generally: consider the case of experimental medical treatment and the decision to exploit it or explore others. The reward is the outcome of the treatment and is stochastic.
Now that we recognised that the reward can be a random variable another marginalization of the MDP dynamics allows us to get the expected reward that tells us if we are in state \(S_t=s\), what reward \(R_{t+1}\), in expectation, we get when taking an action \(a\). It is given by,
\[r(s,a) = \mathop{\mathbb{E}}[ R_{t+1} | S_t=s, A_t=a] = \sum_{r \in \mathcal{R}} r \sum_{s \in \mathcal{S}} p(s', r | s , a) \]
This can be written as a matrix \(\mathcal{R}^a_s\).
And to accommodate the case where the reward is a function of the next state we can write the expected reward as
\[r(s,a, s^\prime) = \mathop{\mathbb{E}}[ R_{t+1} | S_t=s, A_t=a, S_{t+1}=s^\prime] = \sum_{r \in \mathcal{R}} r \frac{p(s', r | s , a)}{p(s' | s , a)}\]
Return
To capture the objective, consider first the return defined as a function of the reward sequence after time step \(t\). Note that the return is also called utility in some texts. In the simplest case this function is the total discounted reward,
The discount rate determines the present value of future rewards: a reward received \(k\) time steps in the future is worth only \(γ^{k−1}\) times what it would be worth if it were received immediately. If \(γ <1\), the infinite sum above has a finite value as long as the reward sequence \({R_k}\) is bounded. If \(γ= 0\), the agent is “myopic” in being concerned only with maximizing immediate rewards: its objective in this case is to learn how to choose \(A_t\) so as to maximize only \(R_{t+1}\). If each of the agent’s actions happened to influence only the immediate reward, not future rewards as well, then a myopic agent could maximize by separately maximizing each immediate reward. But in general, acting to maximize immediate reward can reduce access to future rewards so that the return is reduced. As \(γ\) approaches 1, the return objective takes future rewards into account more strongly; the agent becomes more farsighted.
Notice the two indices needed for its definition - one is the time step \(t\) that manifests where we are in the trajectory and the second index \(k\) is used to index future rewards up to infinity - this is the case of infinite horizon problems where we are not constrained to optimize the agent behavior within the limits of a finite horizon \(T\). If the discount factor \(\gamma < 1\) and the rewards are bounded (\(|R| < R_{max}\)) then the above sum is finite.
The return is itself a random variable - for each trajectory defined by sampling the policy (strategy) of the agent we get a different return. For the Gridworld of the MDP section:
The agent’s behavior is expressed via a policy function\(\pi\) - that tells the agent what action to take for every possible state. The policy is a function of the state and can be:
Deterministic functions of the state the environment is in and by extension, the state that the agent is or believes (think about posterior belief) it is in.
\[a = \pi(s)\]
Stochastic functions of the state expressed as a conditional probability distribution function (conditional pdf) of actions given the current state:
\[a \sim p(A_t=a|S_t=s) = \pi(a|s)\]
The policy is assumed to be stationary i.e. not change with time step \(t\) and it will depend only on the state \(S_t\) i.e. \(A_t=a \sim \pi(.|S_t=s), \forall t > 0\).
Value Functions
The value of a state is the total amount of reward an agent can expect to accumulate over the future, starting from that state. Whereas rewards determine the immediate, intrinsic desirability of environmental states, values indicate the long-term desirability of states after taking into account the states that are likely to follow, and the rewards available in those states.
State value
The state-value function\(v_\pi(s)\) provides a notion of the long-term value of state \(s\). It is equivalent to what other literature calls expected utility . It is defined as the expected_ return starting at state \(s\) and following policy \(\pi(a|s)\),
The expectation is obviously due to the fact that \(G_t\) are random variables since the sequence of states of each potential trajectory starting from \(s\) is dictated by the policy and the stochastic transition model. As an example, assuming that there are just two possible trajectories from state \(s{11}\) whose returns were calculated above, the value function of state \(s_{11}\) will be
One corner case is interesting - if we make \(\gamma=0\) then \(v_\pi(s)\) becomes the average of instantaneous rewards we can get from that state.
Action value
We also define the action-value function\(q_\pi(s,a)\) as the expected return starting from the state \(s\), taking action \(a\) and following policy \(\pi(a|s)\).
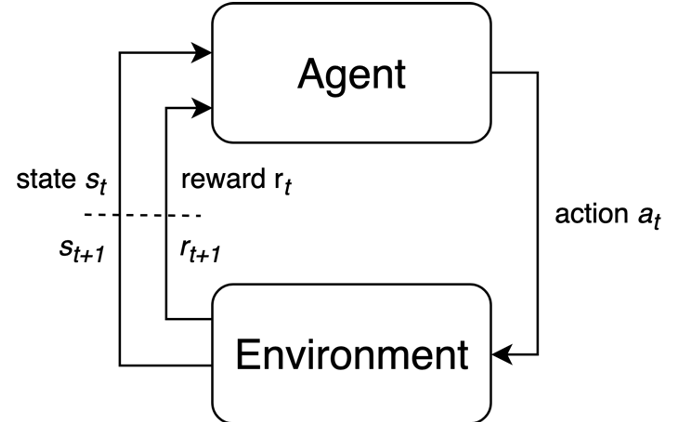 Agent-Environment Interface
Agent-Environment Interface This generic interface between the agent and the environment captures many problems outside of pure MDP including RL. The environment’s state in non-MDP problems can be experienced via sensor observations and the agent will build its own state estimate internally
This generic interface between the agent and the environment captures many problems outside of pure MDP including RL. The environment’s state in non-MDP problems can be experienced via sensor observations and the agent will build its own state estimate internally