In this chapter we look at the training aspects of DNNs and investigate schemes that can help us avoid overfitting.
L2 regularization
This is perhaps the most common form of regularization. It can be implemented by penalizing the squared magnitude of all parameters directly in the objective.
where \(l\) is the hidden layer index and \(W\) is the weight tensor.
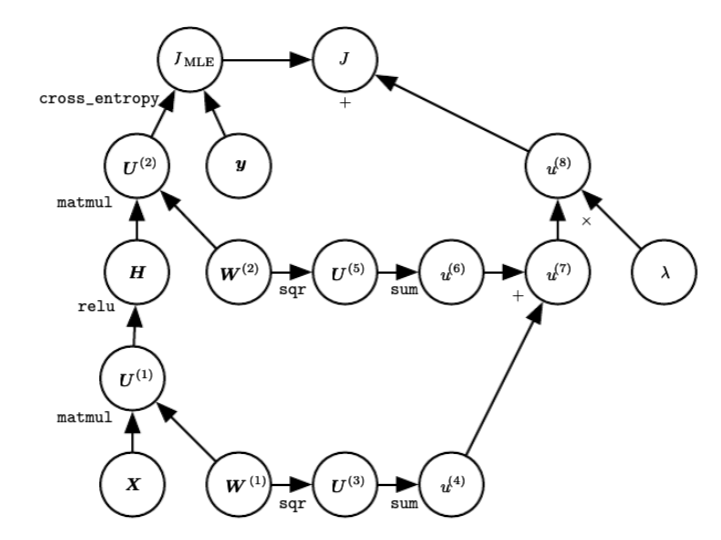
The L2 regularization has the intuitive interpretation of heavily penalizing peaky weight vectors and preferring diffuse weight vectors. Due to multiplicative interactions between weights and inputs this has the appealing property of encouraging the network to use all of its inputs a little rather than some of its inputs a lot. The following figure presents a computational graph of a regularized DNN.
Regularized DNN computational graph
L1 regularization
This is another relatively common form of regularization, where for each weight \(w\) we add the term \(\lambda \mid w \mid\) to the objective. The L1 regularization has the intriguing property that it leads the weight vectors to become sparse during optimization (i.e. exactly zero). In other words, neurons with L1 regularization end up using only a sparse subset of their most important inputs and become nearly invariant to the “noisy” inputs. In comparison, final weight vectors from L2 regularization are usually diffuse, small numbers. In practice, if you are not concerned with explicit feature selection, L2 regularization can be expected to give superior performance over L1. Tools that do model size optimization (e.g. quantization of the model parameters) are typically involved and close to zero parameters are eliminated.
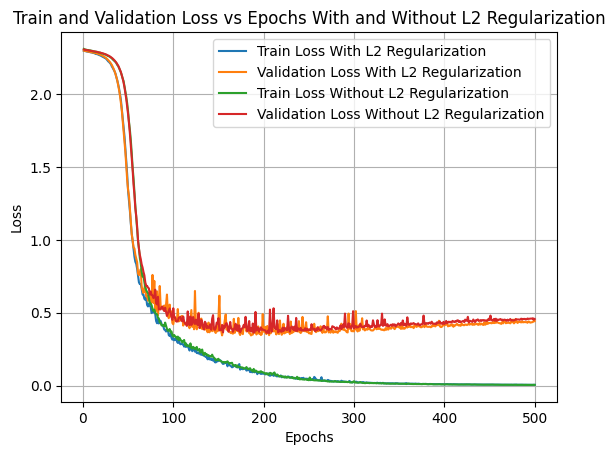
Example of applying L2 regularization
In the CNN MNIST example below notice that the application of L2 regualization is simply done by adding the weight_decay parameter to the optimizer.
import torchimport torch.nn as nnimport torch.optim as optimimport torch.nn.functional as Ffrom torchvision import datasets, transformsimport matplotlib.pyplot as pltfrom sklearn.model_selection import train_test_splitfrom tqdm import tqdm# Check if GPU is available and use itdevice = torch.device('cuda'if torch.cuda.is_available() else'cpu')# Define a simple CNN modelclass SimpleCNN(nn.Module):def__init__(self):super(SimpleCNN, self).__init__()self.conv1 = nn.Conv2d(1, 10, kernel_size=5)self.conv2 = nn.Conv2d(10, 20, kernel_size=5)self.fc1 = nn.Linear(320, 50)self.fc2 = nn.Linear(50, 10)def forward(self, x): x = F.relu(F.max_pool2d(self.conv1(x), 2)) x = F.relu(F.max_pool2d(self.conv2(x), 2)) x = x.view(-1, 320) x = F.relu(self.fc1(x)) x =self.fc2(x)return F.log_softmax(x, dim=1)# Set up training parametersbatch_size =64learning_rate =0.01weight_decay =1e-4# L2 regularization parameter# Load the datasettrain_dataset = datasets.MNIST('../data', train=True, download=True, transform=transforms.ToTensor())# Note that we purposefully limit the number of training data to overfit the modeltrain_data, val_data = train_test_split(train_dataset, test_size=0.99, random_state=42)train_loader = torch.utils.data.DataLoader(train_data, batch_size=batch_size, shuffle=True)val_loader = torch.utils.data.DataLoader(val_data, batch_size=batch_size, shuffle=False)# Initialize the model, loss function, and optimizers (with and without L2 regularization)model_with_l2 = SimpleCNN().to(device)model_without_l2 = SimpleCNN().to(device)criterion = nn.NLLLoss()optimizer_with_l2 = optim.SGD(model_with_l2.parameters(), lr=learning_rate, weight_decay=weight_decay)optimizer_without_l2 = optim.SGD(model_without_l2.parameters(), lr=learning_rate, weight_decay=0)# Training loop for both optimizersnum_epochs =500train_losses_with_l2 = []val_losses_with_l2 = []train_losses_without_l2 = []val_losses_without_l2 = []# Training with L2 Regularizationmodel_with_l2.train()for epoch in tqdm(range(num_epochs), desc="L2 Reg Model Epoch Progress", position=0): total_train_loss =0for batch_idx, (data, target) inenumerate(train_loader): data, target = data.to(device), target.to(device) optimizer_with_l2.zero_grad() # Zero the gradients output = model_with_l2(data) # Forward pass loss = criterion(output, target) # Compute the loss loss.backward() # Backpropagate the gradients optimizer_with_l2.step() # Update the weights total_train_loss += loss.item() avg_train_loss = total_train_loss /len(train_loader) train_losses_with_l2.append(avg_train_loss)#print(f'Epoch {epoch + 1} [With L2]: Train Loss: {avg_train_loss:.6f}')# Validation loss model_with_l2.eval() total_val_loss =0with torch.no_grad():for data, target in val_loader: data, target = data.to(device), target.to(device) output = model_with_l2(data) loss = criterion(output, target) total_val_loss += loss.item() avg_val_loss = total_val_loss /len(val_loader) val_losses_with_l2.append(avg_val_loss)#print(f'Epoch {epoch + 1} [With L2]: Validation Loss: {avg_val_loss:.6f}')# Training without L2 Regularizationmodel_without_l2.train()for epoch in tqdm(range(num_epochs), desc="Unreg Model Epoch Progress", position=0): total_train_loss =0for batch_idx, (data, target) inenumerate(train_loader): data, target = data.to(device), target.to(device) optimizer_without_l2.zero_grad() # Zero the gradients output = model_without_l2(data) # Forward pass loss = criterion(output, target) # Compute the loss loss.backward() # Backpropagate the gradients optimizer_without_l2.step() # Update the weights total_train_loss += loss.item() avg_train_loss = total_train_loss /len(train_loader) train_losses_without_l2.append(avg_train_loss)#print(f'Epoch {epoch + 1} [Without L2]: Train Loss: {avg_train_loss:.6f}')# Validation loss model_without_l2.eval() total_val_loss =0with torch.no_grad():for data, target in val_loader: data, target = data.to(device), target.to(device) output = model_without_l2(data) loss = criterion(output, target) total_val_loss += loss.item() avg_val_loss = total_val_loss /len(val_loader) val_losses_without_l2.append(avg_val_loss)#print(f'Epoch {epoch + 1} [Without L2]: Validation Loss: {avg_val_loss:.6f}')
L2 Reg Model Epoch Progress: 100%|██████████| 500/500 [10:37<00:00, 1.27s/it]
Unreg Model Epoch Progress: 100%|██████████| 500/500 [10:49<00:00, 1.30s/it]
# Plotting Train and Validation Loss vs Epochs for both casesplt.plot(range(1, num_epochs +1), train_losses_with_l2, label='Train Loss With L2 Regularization')plt.plot(range(1, num_epochs +1), val_losses_with_l2, label='Validation Loss With L2 Regularization')plt.plot(range(1, num_epochs +1), train_losses_without_l2, label='Train Loss Without L2 Regularization')plt.plot(range(1, num_epochs +1), val_losses_without_l2, label='Validation Loss Without L2 Regularization')plt.xlabel('Epochs')plt.ylabel('Loss')plt.title('Train and Validation Loss vs Epochs With and Without L2 Regularization')plt.legend()plt.grid(True)plt.show()
Dropout
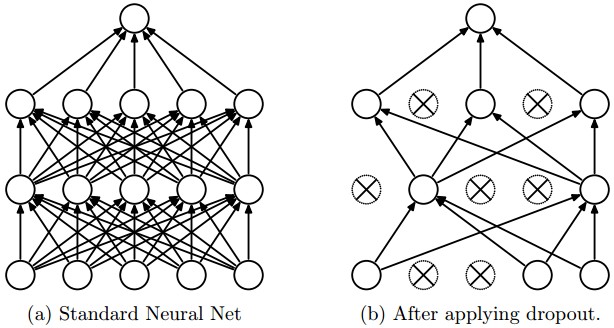
This is an extremely effective, simple regularization technique by Srivastava et al. in Dropout: A Simple Way to Prevent Neural Networks from Overfitting that complements the other methods (L1, L2). While training, dropout is implemented by only keeping a neuron active with some probability \(p\) (a hyperparameter), or setting it to zero otherwise.
During training, Dropout can be interpreted as sampling a Neural Network within the full Neural Network, and only updating the parameters of the sampled network based on the input data. (However, the exponential number of possible sampled networks are not independent because they share the parameters.) During testing there is no dropout applied, with the interpretation of evaluating an averaged prediction across the exponentially-sized ensemble of all sub-networks.
Vanilla dropout in an example 3-layer Neural Network would be implemented as follows:
""" Vanilla Dropout: Not recommended implementation (see notes below) """p =0.5# probability of keeping a unit active. higher = less dropoutdef train_step(X):""" X contains the data """# forward pass for example 3-layer neural network H1 = np.maximum(0, np.dot(W1, X) + b1) U1 = np.random.rand(*H1.shape) < p # first dropout mask H1 *= U1 # drop! H2 = np.maximum(0, np.dot(W2, H1) + b2) U2 = np.random.rand(*H2.shape) < p # second dropout mask H2 *= U2 # drop! out = np.dot(W3, H2) + b3# backward pass: compute gradients... (not shown)# perform parameter update... (not shown)def predict(X):# ensembled forward pass H1 = np.maximum(0, np.dot(W1, X) + b1) * p # NOTE: scale the activations H2 = np.maximum(0, np.dot(W2, H1) + b2) * p # NOTE: scale the activations out = np.dot(W3, H2) + b3
In the code above, inside the train_step function we have performed dropout twice: on the first hidden layer and on the second hidden layer. It is also possible to perform dropout right on the input layer, in which case we would also create a binary mask for the input \(X\). The backward pass remains unchanged, but of course has to take into account the generated masks \(U1,U2\).
Crucially, note that in the predict function we are not dropping anymore, but we are performing a scaling of both hidden layer outputs by \(p\). This is important because at test time all neurons see all their inputs, so we want the outputs of neurons at test time to be identical to their expected outputs at training time. For example, in case of \(p = 0.5\), the neurons must halve their outputs at test time to have the same output as they had during training time (in expectation). To see this, consider an output of a neuron before dropout, lets call it \(x\). With dropout, the expected output from this neuron will become \(px + (1-p)0\), because the neuron’s output will be set to zero with probability \(1-p\). At test time, when we keep the neuron always active, we must adjust \(x \rightarrow px\) to keep the same expected output.
Note
It can also be shown that performing this attenuation at test time can be related to the process of iterating over all the possible binary masks (and therefore all the exponentially many sub-networks) and computing their ensemble prediction.
However, it is not very desirable to scale the activations by \(p\) during inference expending a computational penalty when we serve the model and therefore we use inverted dropout, which performs the scaling at train time, leaving the forward pass at test time untouched. Additionally, this has the appealing property that the prediction code can remain untouched when you decide to tweak where you apply dropout, or if at all. Inverted dropout looks as follows:
""" Inverted Dropout: Recommended implementation example.We drop and scale at train time and don't do anything at test time."""p =0.5# probability of keeping a unit active. higher = less dropoutdef train_step(X):# forward pass for example 3-layer neural network H1 = np.maximum(0, np.dot(W1, X) + b1) U1 = (np.random.rand(*H1.shape) < p) / p # first dropout mask. Notice /p! H1 *= U1 # drop! H2 = np.maximum(0, np.dot(W2, H1) + b2) U2 = (np.random.rand(*H2.shape) < p) / p # second dropout mask. Notice /p! H2 *= U2 # drop! out = np.dot(W3, H2) + b3# backward pass: compute gradients... (not shown)# perform parameter update... (not shown)def predict(X):# ensembled forward pass H1 = np.maximum(0, np.dot(W1, X) + b1) # no scaling necessary H2 = np.maximum(0, np.dot(W2, H1) + b2) out = np.dot(W3, H2) + b3
Dropout falls into a more general category of methods that introduce stochastic behavior in the forward pass of the network. During testing, the noise is marginalized over analytically (as is the case with dropout when multiplying by \(p\)), or numerically (e.g. via sampling, by performing several forward passes with different random decisions and then averaging over them). An example of other research in this direction includes DropConnect, where a random set of weights is instead set to zero during forward pass. As foreshadowing, Convolutional Neural Networks also take advantage of this theme with methods such as stochastic pooling, fractional pooling, and data augmentation. We will go into details of these methods later.
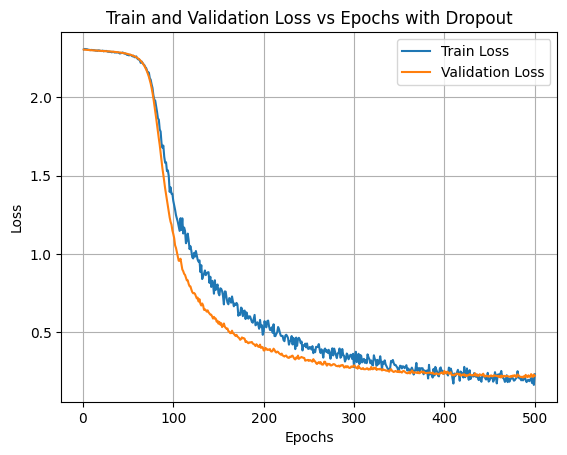
In practice, it is most common to use a single, global L2 regularization strength that is cross-validated. It is also common to combine this with dropout applied after all layers. The value of \(p = 0.5\) is a reasonable default, but this can be tuned on validation data. Note that dropout’s usage has been limited by another technique called Batch Normalization and there is some interesting interference between the two for those that want to dig further.
import torchimport torch.nn as nnimport torch.optim as optimimport torch.nn.functional as Ffrom torchvision import datasets, transformsimport matplotlib.pyplot as pltfrom sklearn.model_selection import train_test_split# Define a simple CNN modelclass SimpleCNN(nn.Module):def__init__(self):super(SimpleCNN, self).__init__()self.conv1 = nn.Conv2d(1, 10, kernel_size=5)self.conv2 = nn.Conv2d(10, 20, kernel_size=5)self.fc1 = nn.Linear(320, 50)self.fc2 = nn.Linear(50, 10)self.dropout = nn.Dropout(p=0.5)def forward(self, x): x = F.relu(F.max_pool2d(self.conv1(x), 2)) x =self.dropout(x) x = F.relu(F.max_pool2d(self.conv2(x), 2)) x =self.dropout(x) x = x.view(-1, 320) x = F.relu(self.fc1(x)) x =self.fc2(x)return F.log_softmax(x, dim=1)# Set up training parametersbatch_size =64learning_rate =0.01weight_decay =1e-4# L2 regularization parameter# Load the datasettrain_dataset = datasets.MNIST('../data', train=True, download=True, transform=transforms.ToTensor())train_data, val_data = train_test_split(train_dataset, test_size=0.99, random_state=42)train_loader = torch.utils.data.DataLoader(train_data, batch_size=batch_size, shuffle=True)val_loader = torch.utils.data.DataLoader(val_data, batch_size=batch_size, shuffle=False)# Check if GPU is available and use itdevice = torch.device('cuda'if torch.cuda.is_available() else'cpu')# Initialize the model, loss function, and optimizermodel = SimpleCNN().to(device)criterion = nn.NLLLoss()optimizer = optim.SGD(model.parameters(), lr=learning_rate, weight_decay=weight_decay)# Training loopnum_epochs =500train_losses = []val_losses = []for epoch in tqdm(range(num_epochs), desc="Epoch Progress", position=0): model.train() total_train_loss =0for batch_idx, (data, target) inenumerate(train_loader): data, target = data.to(device), target.to(device) optimizer.zero_grad() # Zero the gradients output = model(data) # Forward pass loss = criterion(output, target) # Compute the loss loss.backward() # Backpropagate the gradients optimizer.step() # Update the weights total_train_loss += loss.item() avg_train_loss = total_train_loss /len(train_loader) train_losses.append(avg_train_loss)#print(f'Epoch {epoch + 1}: Train Loss: {avg_train_loss:.6f}')# Validation loss model.eval() total_val_loss =0with torch.no_grad():for data, target in val_loader: data, target = data.to(device), target.to(device) output = model(data) loss = criterion(output, target) total_val_loss += loss.item() avg_val_loss = total_val_loss /len(val_loader) val_losses.append(avg_val_loss)#print(f'Epoch {epoch + 1}: Validation Loss: {avg_val_loss:.6f}')# Plotting Train and Validation Loss vs Epochsplt.plot(range(1, num_epochs +1), train_losses, label='Train Loss')plt.plot(range(1, num_epochs +1), val_losses, label='Validation Loss')plt.xlabel('Epochs')plt.ylabel('Loss')plt.title('Train and Validation Loss vs Epochs with Dropout')plt.legend()plt.grid(True)plt.show()
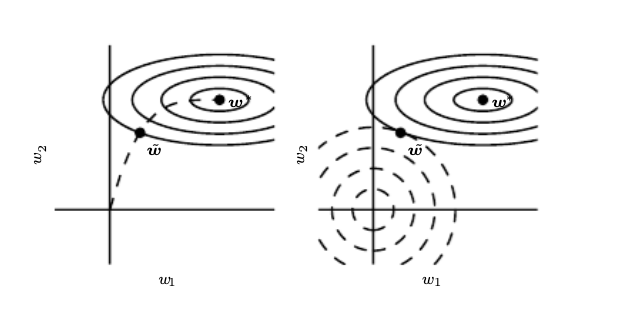
In these notes we focused on approaches that have some conceptual depth. We avoid treating extensively techniques that belong to the category of experiment management. For example early stopping is based on the experiment manager that is monitoring the validation loss and stops training when it observes that the validation error increased while at the same time retrieves the best model that has been trained to the data scientist. This does not stop the approach being one of the most popular regularization approaches as it can be seen as an L2 regularizer as shown below.
Early stopping trajectory vs L2 regularization trajectory
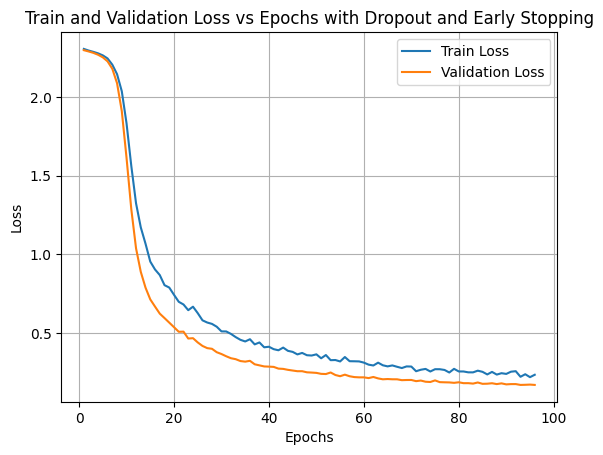
import torchimport torch.nn as nnimport torch.optim as optimimport torch.nn.functional as Ffrom torchvision import datasets, transformsimport matplotlib.pyplot as pltfrom sklearn.model_selection import train_test_splitimport numpy as np# Define a simple CNN modelclass SimpleCNN(nn.Module):def__init__(self):super(SimpleCNN, self).__init__()self.conv1 = nn.Conv2d(1, 10, kernel_size=5)self.conv2 = nn.Conv2d(10, 20, kernel_size=5)self.fc1 = nn.Linear(320, 50)self.fc2 = nn.Linear(50, 10)self.dropout = nn.Dropout(p=0.5)def forward(self, x): x = F.relu(F.max_pool2d(self.conv1(x), 2)) x =self.dropout(x) x = F.relu(F.max_pool2d(self.conv2(x), 2)) x =self.dropout(x) x = x.view(-1, 320) x = F.relu(self.fc1(x)) x =self.fc2(x)return F.log_softmax(x, dim=1)# Set up training parametersbatch_size =64learning_rate =0.01weight_decay =1e-4# L2 regularization parameterpatience =3# Early stopping patience# Load the datasettrain_dataset = datasets.MNIST('../data', train=True, download=True, transform=transforms.ToTensor())train_data, val_data = train_test_split(train_dataset, test_size=0.95, random_state=42)train_loader = torch.utils.data.DataLoader(train_data, batch_size=batch_size, shuffle=True)val_loader = torch.utils.data.DataLoader(val_data, batch_size=batch_size, shuffle=False)# Check if GPU is available and use itdevice = torch.device('cuda'if torch.cuda.is_available() else'cpu')# Initialize the model, loss function, and optimizermodel = SimpleCNN().to(device)criterion = nn.NLLLoss()optimizer = optim.SGD(model.parameters(), lr=learning_rate, weight_decay=weight_decay)# Training loop with Early Stoppingnum_epochs =500train_losses = []val_losses = []min_val_loss = np.infpatience_counter =0for epoch in tqdm(range(num_epochs), desc="Epoch Progress", position=0): model.train() total_train_loss =0for batch_idx, (data, target) inenumerate(train_loader): data, target = data.to(device), target.to(device) optimizer.zero_grad() # Zero the gradients output = model(data) # Forward pass loss = criterion(output, target) # Compute the loss loss.backward() # Backpropagate the gradients optimizer.step() # Update the weights total_train_loss += loss.item() avg_train_loss = total_train_loss /len(train_loader) train_losses.append(avg_train_loss)#print(f'Epoch {epoch + 1}: Train Loss: {avg_train_loss:.6f}')# Validation loss model.eval() total_val_loss =0with torch.no_grad():for data, target in val_loader: data, target = data.to(device), target.to(device) output = model(data) loss = criterion(output, target) total_val_loss += loss.item() avg_val_loss = total_val_loss /len(val_loader) val_losses.append(avg_val_loss)#print(f'Epoch {epoch + 1}: Validation Loss: {avg_val_loss:.6f}')# Early stopping checkif avg_val_loss < min_val_loss: min_val_loss = avg_val_loss patience_counter =0 best_model_state = model.state_dict()else: patience_counter +=1if patience_counter >= patience:print(f'Early stopping triggered after {epoch +1} epochs.')break# Load the best model state (if early stopping was triggered)model.load_state_dict(best_model_state)# Plotting Train and Validation Loss vs Epochsplt.plot(range(1, len(train_losses) +1), train_losses, label='Train Loss')plt.plot(range(1, len(val_losses) +1), val_losses, label='Validation Loss')plt.xlabel('Epochs')plt.ylabel('Loss')plt.title('Train and Validation Loss vs Epochs with Dropout and Early Stopping')plt.legend()plt.grid(True)plt.show()