Markov Decision Processes#
Warning
Many of the algorithms presented here like policy and value iteration have been developed in older repos such as this and this. This site is being migrated to be compatible with Farama and their Gymnasium tooling. See Farama.org for additional information.
We started looking at different agent behavior architectures starting from the planning agents where the model of the environment is known and with no interaction with it, the agent improves its policy, using this model as well as problem solving and logical reasoning skills.
We now look at agents that can plan by:
Interacting with the environment by receiving reward signals from it during each interaction.
Knowing the model (dynamics) of the environment, they have an internal objective function that they try to optimize based on the experience they accumulate.
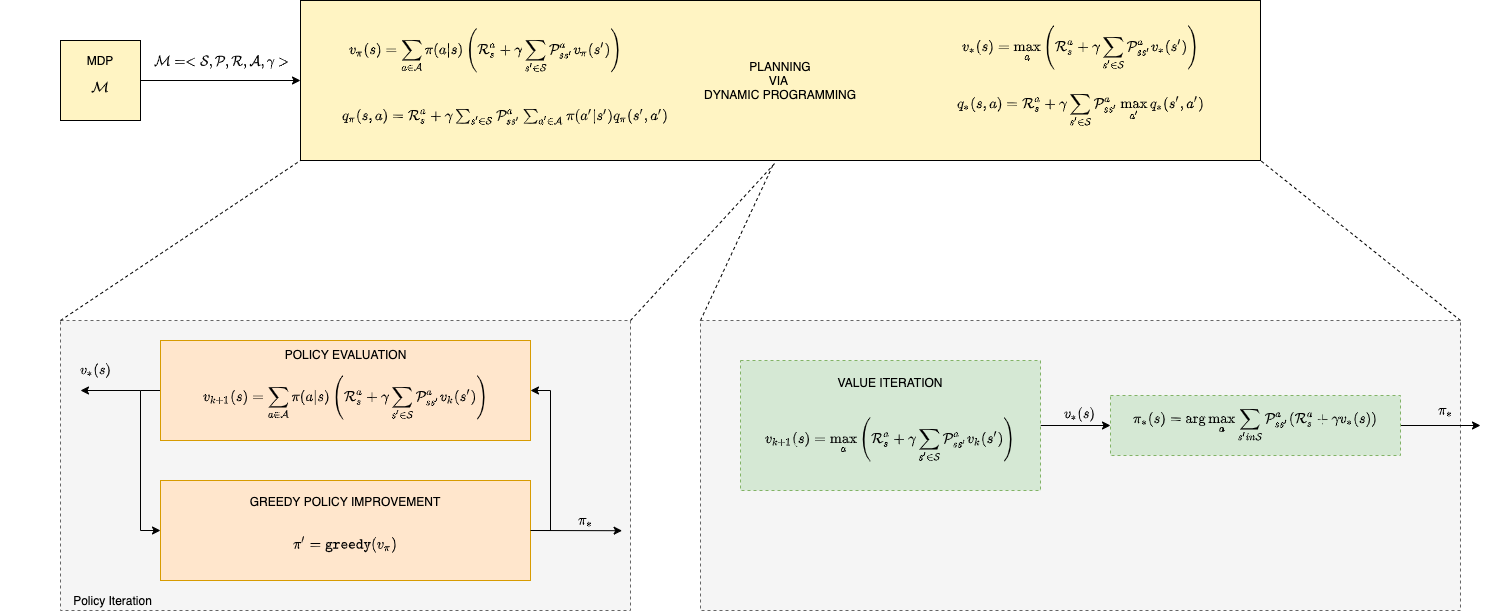
The problem as will see, will be described via a set of four equations called Bellman expectation and Bellman optimality equations that connect the values (utility) with each state or action with the policy (strategy) of the agent. These equations can be solved by Dynamic Programming algorithms to produce the optimal policy that the agent must adopt.
Computationally we will go through approaches that solve the MDP as efficiently as possible - namely, the value and policy iteration algorithms.
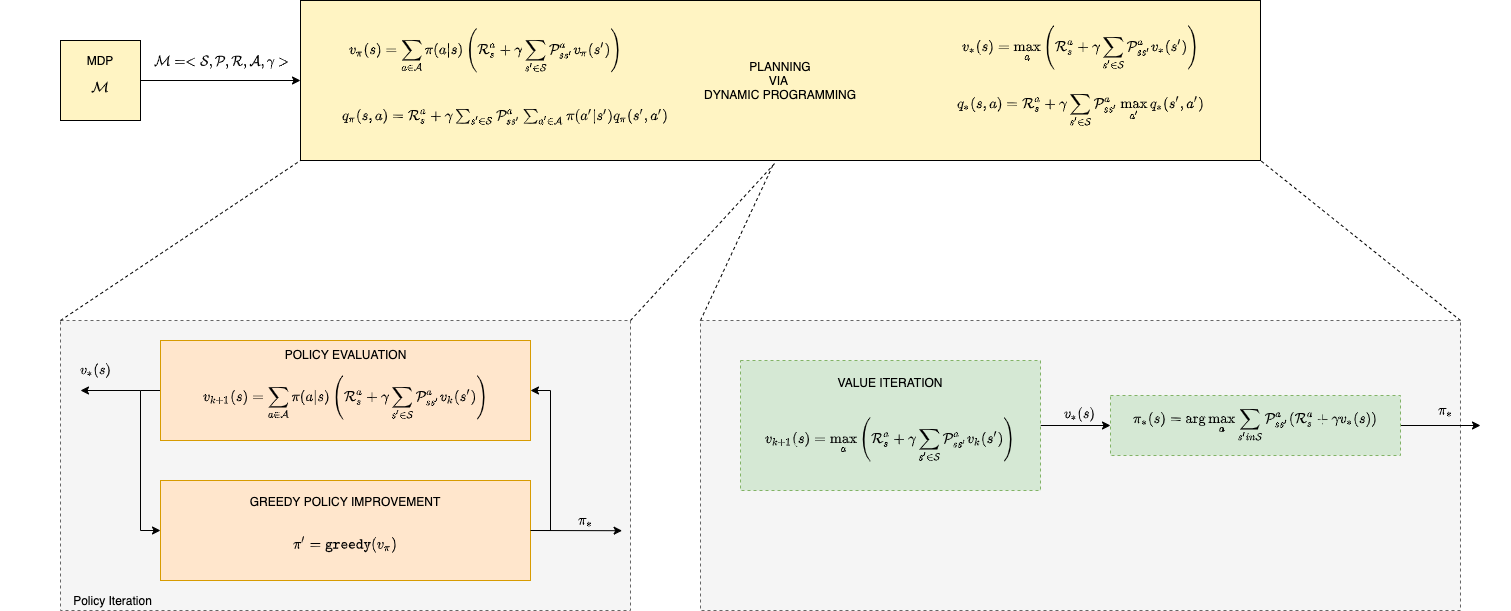
Solving MDP Problems - click this link to display a larger image
{kind=link}
Note
Apart from the notes here that are largely based on David Silver’s (Deep Mind) course material and video lectures, the curious mind will be find additional resources:
in the Richard Sutton’s book - David Silver’s slides and video lectures are based on this book. The code in Python of the book is here
in the suggested book written by Google researchers as well as on OpenAI’s website. The chapters we covered is 1-4.
You may also want to watch Andrew Ng’s, 2018 version of his ML class that includes MDP and RL lectures.