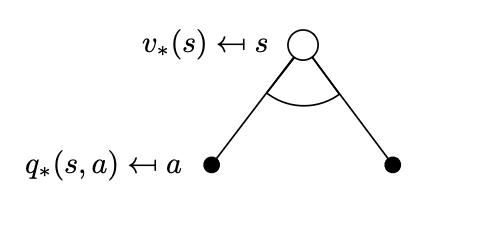Engineering AI Agents
BOOK
Foundations
Training Deep Networks
Perception
Kinematics
State Estimation
Large Language Models
Multimodal Reasoning
Task Planning
Global Planning
Local Planning
Markov Decision Processes
Reinforcement Learning
VLA Agents
COURSES
Introduction to AI
AI for Robotics
Deep Learning for Computer Vision
DATA MINING - BEING PORTED
MEDIA
AI for Robotics
ABOUT ME
Markov Decision Processes
Markov Decision Processes
Optimal Sequential Decision Making
Author
Pantelis Monogioudis
Bellman Equations
Markov Decision Processes
Introduction to MDP
Bellman Expectation Backup
Policy Evaluation (Prediction)
Bellman Optimality Backup
Applying the Bellman Optimality Backup
Policy Improvement (Control)
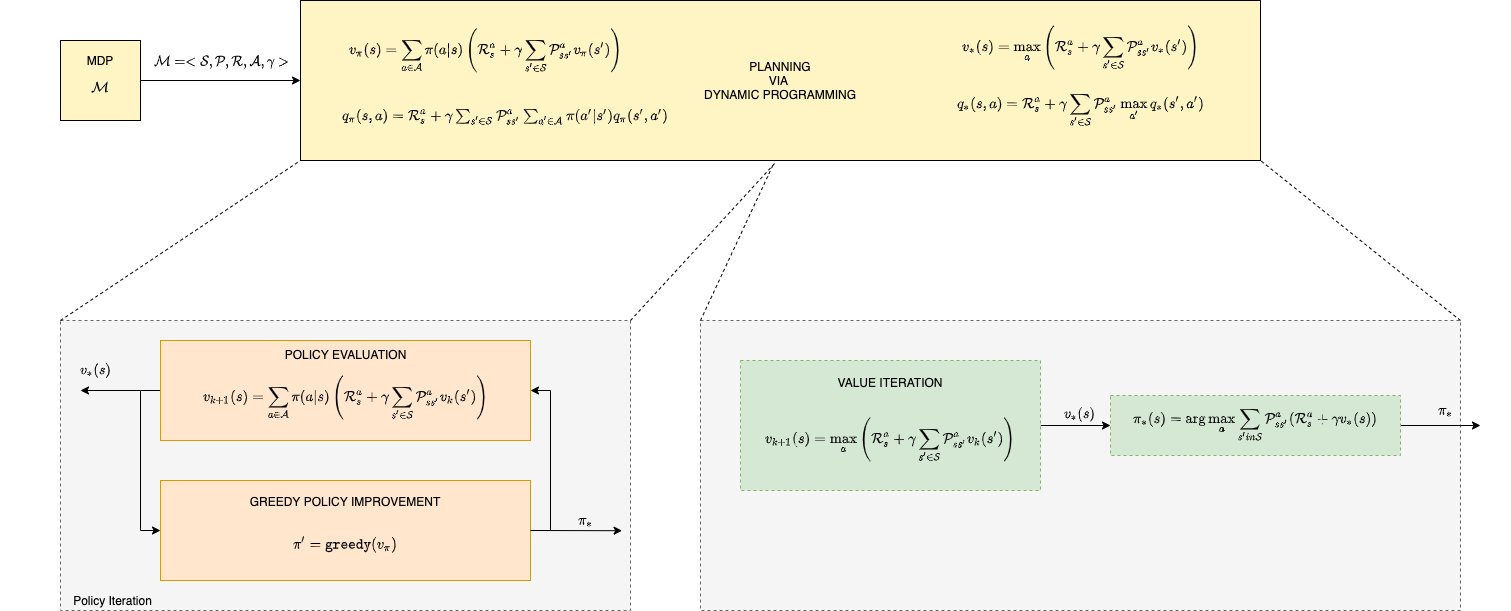
Dynamic Programming Algorithms
Policy Iteration
Policy Iteration Gridworld
Value Iteration
Value Iteration Gridworld
Categories
All
(13)
Applying the Bellman Optimality Backup
Finite State Machine of a a recycling robot and MDP dynamics LUT
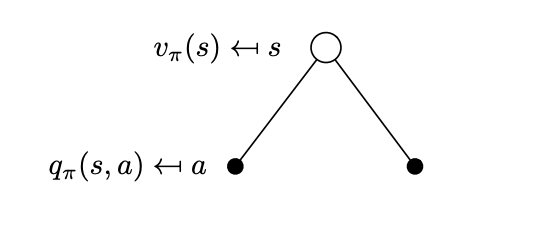
Bellman Expectation Backup
In this section we describe how to calculate the value functions by establishing a recursive relationship similar to the one we did for the return. We replace the…
Bellman Optimality Backup
Now that we can calculate the value functions efficiently via the Bellman expectation recursions, we can now solve the MDP which requires maximize either of the two…
Markov Decision Processes
Many of the algorithms presented here like policy and value iteration have been developed in older repos such as this and this. This site is being migrated to be compatible…
Policy Improvement (Control)
In the policy improvement step we are given the value function and simply apply the greedy heuristic to it.
Policy Iteration
In this section we start developing dynamic programming algorithms that solve a
perfectly known MDP
. In the Bellman expectation backup section we have derived the equations…
No matching items