Engineering AI Agents
BOOK
Foundations
Training Deep Networks
Perception
Kinematics
State Estimation
Large Language Models
Multimodal Reasoning
Task Planning
Global Planning
Local Planning
Markov Decision Processes
Reinforcement Learning
VLA Agents
COURSES
Introduction to AI
AI for Robotics
Deep Learning for Computer Vision
DATA MINING - BEING PORTED
MEDIA
AI for Robotics
ABOUT ME
Multimodal Reasoning
Multimodal Reasoning
Grounding language in perception.
Author
Pantelis Monogioudis
Multimodal Reasoning
Text Tokenization
Word2Vec Embeddings
Word2Vec from scratch
Word2Vec Tensorflow Tutorial
Language Models
Transformers and Self-Attention
Single-head self-attention
Multi-head self-attention
Positional Embeddings
Batch Normalization
Layer Normalization (LN)
Vision Transformer Paper
Vision Transformer (ViT) in PyTorch
Contrastive Language-Image Pretraining (CLIP)
CLIP Paper
BLIP-2
BLIP-2 Paper
Visual Instruction Tuning - LlaVa
LLaVa Paper
Categories
All
(15)
CLIP Paper
The CLIP paper, one of the most beautifully written papers in the AI domain, is a must-read just for this reason alone: you can adopt the template for your own papers or…
Contrastive Language-Image Pretraining (CLIP)
This is shamelessly copied from the MIT Foundations of Computer Vision Book by Prof. William T. Freeman et al.
Language Models
These notes heavily borrowing from the CS224N set of notes on Language Models.
Multi-head self-attention
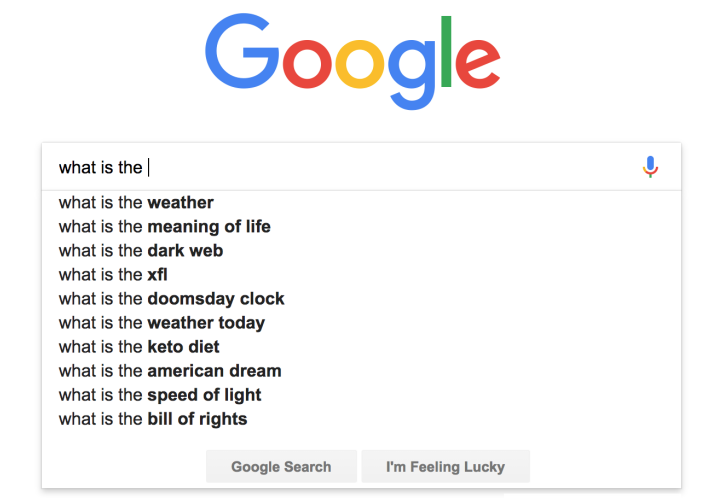
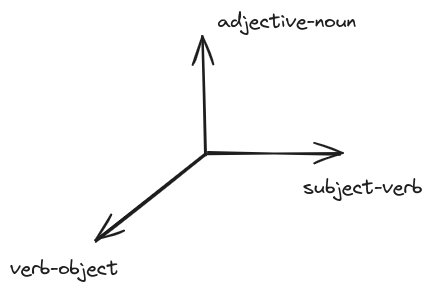
Earlier we have seen examples with the token
bear
being in multiple grammatical patterns that also influence its meaning. For example, we have seen the subject-verb-object…
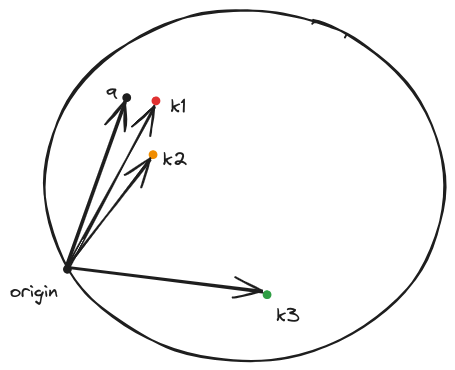
Single-head self-attention
In the simple attention mechanism, the attention weights are computed
deterministically
from the input context. We call the combination of context-free embedding (eg…
Transformers and Self-Attention
For the explanation of decoder-based architectures such as those used by GPT, please see the repo https://github.com/pantelis/femtotransformers and the embedded comments…
Vision Transformer Paper
Word2Vec Embeddings
In the so called classical NLP, words were treated as atomic symbols, e.g.
hotel
,
conference
,
walk
and they were represented with on-hot encoded (sparse) vectors e.g.
No matching items