import torch
from torch import nn
class PatchEmbedding(nn.Module):
def __init__(self, in_channels=3, patch_size=16, emb_size=768):
super().__init__()
self.patch_size = patch_size
self.proj = nn.Conv2d(in_channels, emb_size, kernel_size=patch_size, stride=patch_size)
def forward(self, x):
x = self.proj(x) # (B, emb_size, H/patch_size, W/patch_size)
x = x.flatten(2) # (B, emb_size, N_patches)
x = x.transpose(1, 2) # (B, N_patches, emb_size)
return xVision Transformer (ViT) in PyTorch
This notebook walks you through building a Vision Transformer (ViT) using PyTorch. We assume you’re familiar with Transformer architectures in NLP (decoder-based transformers). Here the transformer implements the encoder arhitecture and the ViT treats an image as a sequence of patches, similar to tokens in NLP.
Note
We have used some pictures out of the excellent book Foundations of Computer Vision as taught in this course. Note that the pictures refer to a query that is text and the key/value that is an image - its a different task than what the code addresses which is image classification and the query is an image and the key/value is a sequence of patches.
Patch Embedding
The first step in ViT is to split the image into fixed-size patches and project them into a latent embedding space using a convolution layer.
![]()
Positional Encoding
Adds positional information to the patch embeddings using learnable positional embeddings.
class PositionalEncoding(nn.Module):
def __init__(self, seq_len, emb_size):
super().__init__()
self.pos_embedding = nn.Parameter(torch.randn(1, seq_len, emb_size))
def forward(self, x):
return x + self.pos_embedding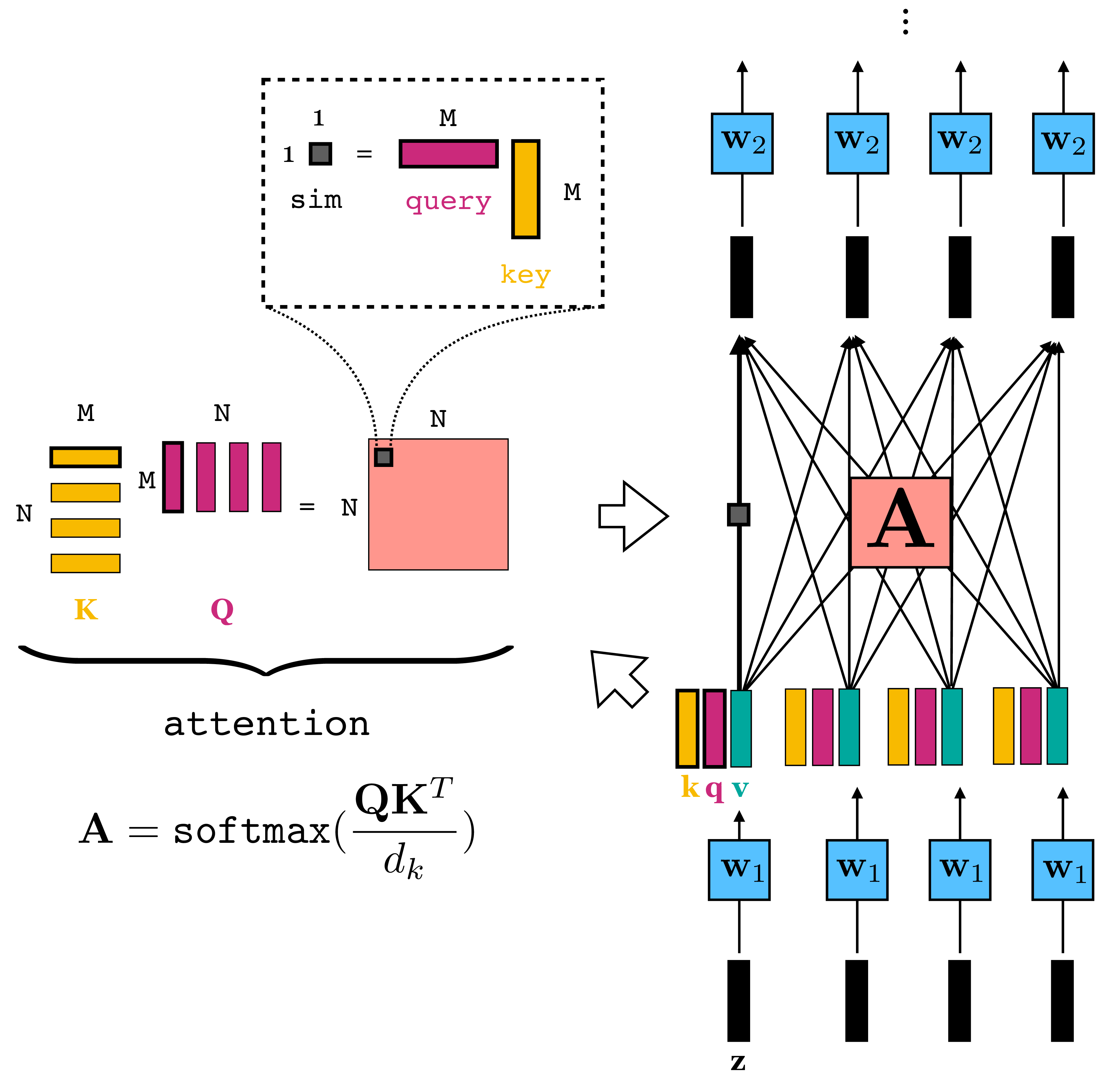
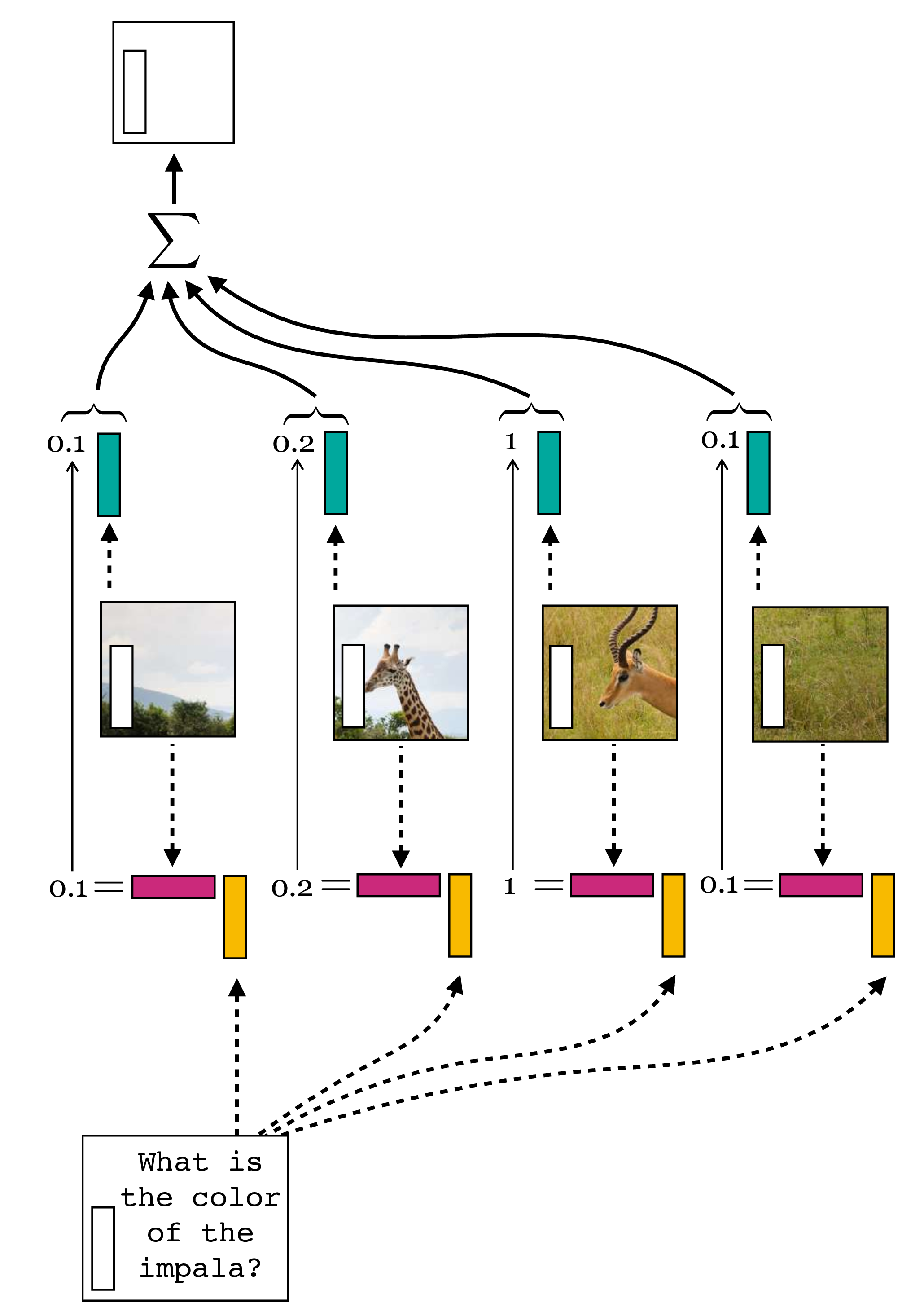
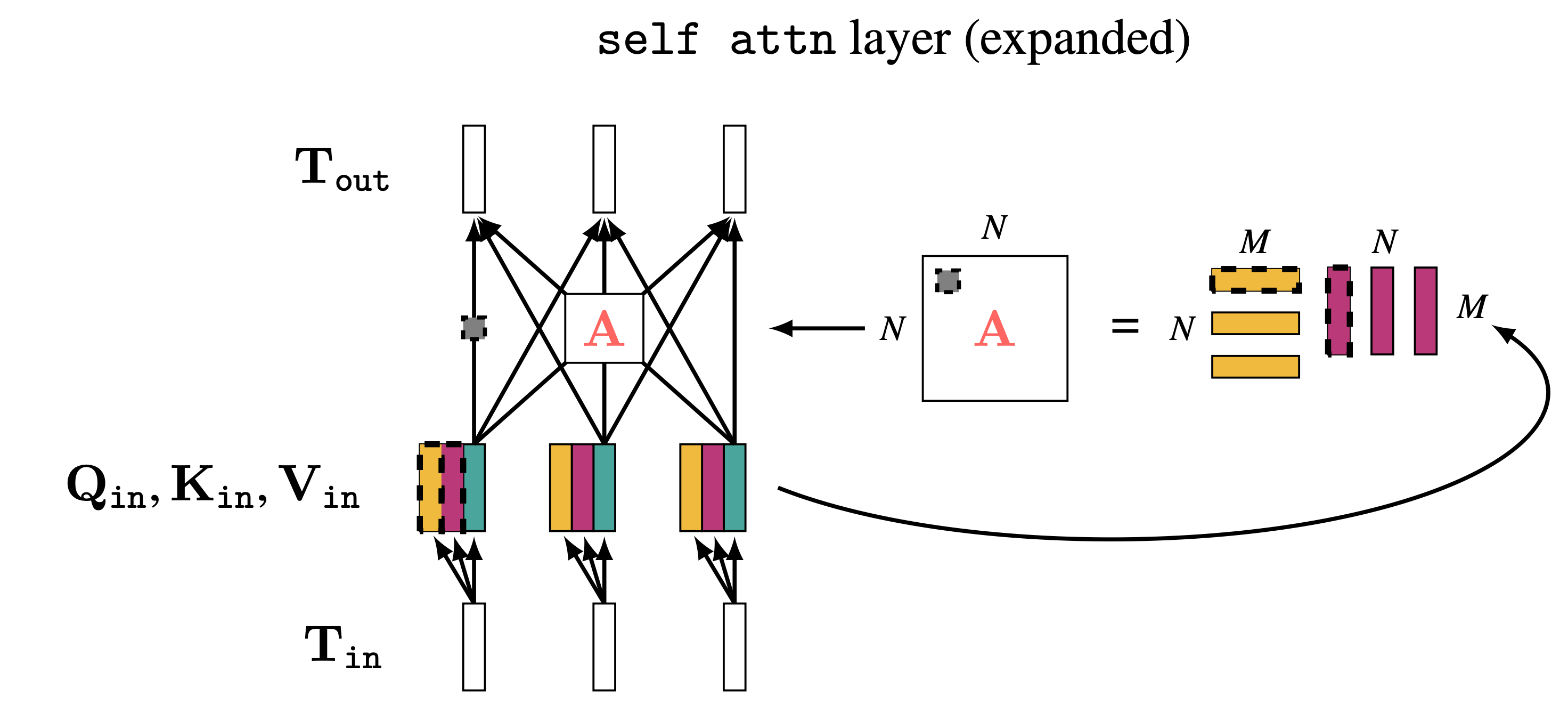
Transformer Encoder Block
Each block contains multi-head self-attention, a feed-forward network, and residual connections.
class TransformerEncoderBlock(nn.Module):
def __init__(self, emb_size, num_heads, ff_hidden_mult=4, dropout=0.1):
super().__init__()
self.norm1 = nn.LayerNorm(emb_size)
self.attn = nn.MultiheadAttention(emb_size, num_heads, dropout=dropout)
self.norm2 = nn.LayerNorm(emb_size)
self.ff = nn.Sequential(
nn.Linear(emb_size, ff_hidden_mult * emb_size),
nn.GELU(),
nn.Linear(ff_hidden_mult * emb_size, emb_size),
nn.Dropout(dropout)
)
def forward(self, x):
x = x + self.attn(self.norm1(x), self.norm1(x), self.norm1(x))[0]
x = x + self.ff(self.norm2(x))
return xClassification Head
Uses the CLS token to produce class predictions after the encoder blocks.
class ClassificationHead(nn.Module):
def __init__(self, emb_size, num_classes):
super().__init__()
self.norm = nn.LayerNorm(emb_size)
self.fc = nn.Linear(emb_size, num_classes)
def forward(self, x):
x = self.norm(x)
return self.fc(x[:, 0])Vision Transformer Model
Combines all parts together into a full ViT model. Note that this model is replaced further below with a model configured for the CIFAR-10 dataset.
class VisionTransformer(nn.Module):
def __init__(self, in_channels=3, patch_size=16, emb_size=768, num_heads=12, num_layers=12, num_classes=1000, img_size=224):
super().__init__()
self.patch_embed = PatchEmbedding(in_channels, patch_size, emb_size)
num_patches = (img_size // patch_size) ** 2
self.pos_embed = PositionalEncoding(num_patches + 1, emb_size)
self.cls_token = nn.Parameter(torch.randn(1, 1, emb_size))
self.encoder = nn.Sequential(*[TransformerEncoderBlock(emb_size, num_heads) for _ in range(num_layers)])
self.head = ClassificationHead(emb_size, num_classes)
def forward(self, x):
x = self.patch_embed(x)
cls_tokens = self.cls_token.expand(x.size(0), -1, -1)
x = torch.cat((cls_tokens, x), dim=1)
x = self.pos_embed(x)
x = self.encoder(x)
return self.head(x)Dataset and Training Prep
Example: Loading CIFAR-10 to train the Vision Transformer. Note something about the transformation needed.
The original Vision Transformer (ViT) architecture was trained on ImageNet, where input images are 224×224 pixels. The model expects this size because the image is split into fixed-size patches (e.g., 16×16), and 224/16 = 14, resulting in 14×14 = 196 patches. This number of tokens (patches) is what the positional embeddings and transformer layers are designed for in ViT-Base.
from torchvision import datasets, transforms
from torch.utils.data import DataLoader
transform = transforms.Compose([
transforms.Resize((224, 224)),
transforms.ToTensor(),
])
train_dataset = datasets.CIFAR10(root='./data', train=True, download=True, transform=transform)
train_loader = DataLoader(train_dataset, batch_size=32, shuffle=True)Having said that the CIFAR10 images are too small for such resizing to make sense. Below we make the modifications to the model to work with CIFAR10 images.
from torchvision import datasets, transforms
from torch.utils.data import DataLoader
transform = transforms.Compose([
# No resizing needed for CIFAR-10 32x32
transforms.ToTensor(),
])
train_dataset = datasets.CIFAR10(root='./data', train=True, download=True, transform=transform)
train_loader = DataLoader(train_dataset, batch_size=32, shuffle=True)class VisionTransformer(nn.Module):
def __init__(self, in_channels=3, patch_size=4, emb_size=192, num_heads=3, num_layers=7, num_classes=10, img_size=32):
super().__init__()
self.patch_embed = PatchEmbedding(in_channels, patch_size, emb_size)
num_patches = (img_size // patch_size) ** 2
self.pos_embed = PositionalEncoding(num_patches + 1, emb_size)
self.cls_token = nn.Parameter(torch.randn(1, 1, emb_size))
self.encoder = nn.Sequential(*[TransformerEncoderBlock(emb_size, num_heads) for _ in range(num_layers)])
self.head = ClassificationHead(emb_size, num_classes)
def forward(self, x):
x = self.patch_embed(x)
cls_tokens = self.cls_token.expand(x.size(0), -1, -1)
x = torch.cat((cls_tokens, x), dim=1)
x = self.pos_embed(x)
x = self.encoder(x)
return self.head(x)Training Loop
Here’s a basic training loop for the CIFAR-10 dataset.
import torch.optim as optim
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
model = VisionTransformer(num_classes=10).to(device)
criterion = nn.CrossEntropyLoss()
optimizer = optim.Adam(model.parameters(), lr=3e-4)
def train(model, dataloader, criterion, optimizer, device, epochs=5):
model.train()
for epoch in range(epochs):
total_loss = 0
correct = 0
total = 0
for images, labels in dataloader:
images, labels = images.to(device), labels.to(device)
optimizer.zero_grad()
outputs = model(images)
loss = criterion(outputs, labels)
loss.backward()
optimizer.step()
total_loss += loss.item()
_, predicted = outputs.max(1)
total += labels.size(0)
correct += predicted.eq(labels).sum().item()
print(f"Epoch {epoch+1}/{epochs}, Loss: {total_loss/len(dataloader):.4f}, Accuracy: {100.*correct/total:.2f}%")
# Train the model
train(model, train_loader, criterion, optimizer, device)Epoch 1/5, Loss: 2.3192, Accuracy: 9.93%
Epoch 2/5, Loss: 2.3102, Accuracy: 10.23%
Epoch 3/5, Loss: 2.3079, Accuracy: 10.20%
Epoch 4/5, Loss: 2.3071, Accuracy: 9.89%
Epoch 5/5, Loss: 2.3063, Accuracy: 9.69%