Multilayer Perceptron (MLP)
Notice that at its core the output of the multihead self attention is a weighted sum of the input tokens. This is a linear combination of the value vectors and the attention block does not have the capacity to learn non-linear relationships. One cat argue that the attention weights and softmax add some non-linearity but this is not enough and the model will not be able to learn complex dependencies. To address this we add an MLP to the output of the multihead self attention.
\[Y = \mathtt{LayerNorm}(\hat Z)\]
\[\tilde X = \mathtt{MLP}(Y) + \hat Z\]
where the MLP uses skip connection and for some implementations a RELU or GELU activation function shown below is used.
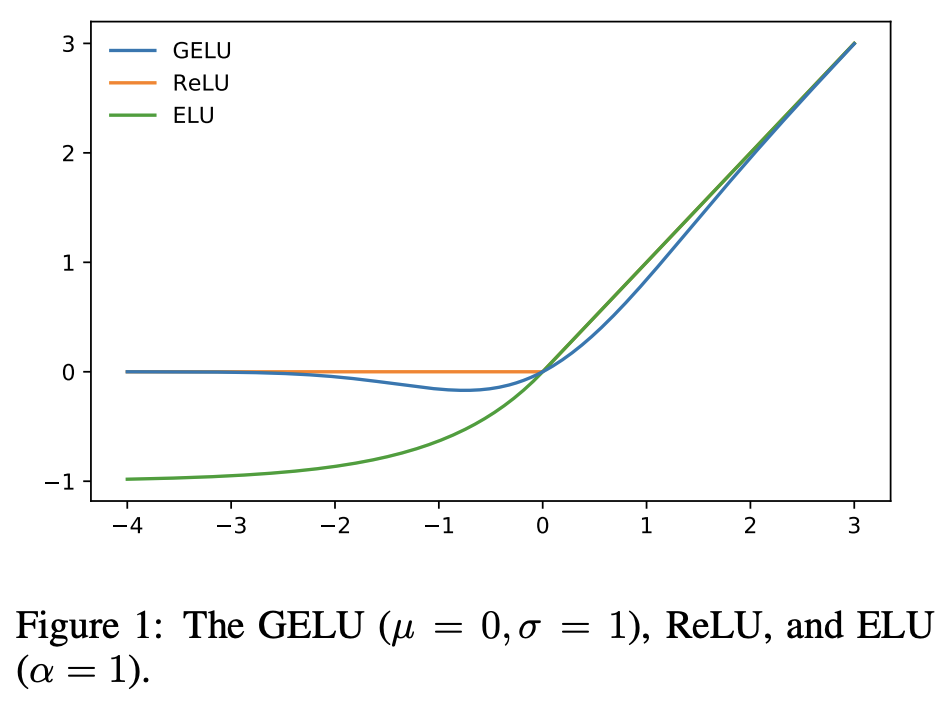
Notably, each token is processed by the MLP independently of the other tokens in the input.
class FeedForward(nn.Module):
def __init__(self, config):
super().__init__()
self.linear_1 = nn.Linear(config.hidden_size, config.intermediate_size)
self.linear_2 = nn.Linear(config.intermediate_size, config.hidden_size)
self.gelu = nn.GELU()
self.dropout = nn.Dropout(config.hidden_dropout_prob)
def forward(self, x):
x = self.linear_1(x)
x = self.gelu(x)
x = self.linear_2(x)
x = self.dropout(x)
return x