Linear Algebra for Machine Learning #
Let me introduce you MIT prof G Strang - probably the best educator in America. He has published this playlist of youtube videos on Linear Algebra.
Linear Algebra recitation for my classes. Recitation was delivered by my TA Shweta Selvaraj Achary.
The corresponding chapter of Ian Goodfellow’s Deep Learning book is what you partially need to know as data scientists at a graduate level but arguably if you are just starting you ought to know 2.1-2.5.
Key Points #
We can now summarize the points to pay attention to, for ML applications. In the following we assume a data matrix $A$ with $m$ rows and $n$ columns. We also assume that the matrix is such that it has $r$ independent rows or columns, called the matrix rank.
Projections #
Its important to understand this basic operator and its geometric interpretation as it is met in problems like Ordinary Least Squares but also all over ML and other fields such as compressed sensing. In the following we assume that the reader is familiar with the concept of vector spaces and subspaces.
Let $S$ be a vector subspace of $\R^n$. For example in $\R^3$, $S$ are the lines and planes going through the origin. The projection operator onto $S$ implements a linear transformation: $\Pi_S: \R^3 →S$. We will stick to $\R^3$ to maintain the ability to plot the operations involved. We also define the orthogonal subspace,
$$S^\perp ≡ \{ \bm w \in \R^3 | \bm w ^T \bm s = 0, ∀ \bm s \in S \} $$
The transformation $\Pi_S$ projects onto space $S$ in the sense that when you apply this operator, every vector $\bm u$ in any other space results in the subspace $S$. In our example above,
$$\Pi_S(\bm u) \in S, \forall \bm u \in \R^3$$
This means that any components of the vector $\bm u$ that belonged to $S^\perp$ are gone when applying the projection operator. Effectively, the original space is decomposed into
$$ \R^3 = S \oplus S^\perp $$
Now we can treat projections onto specific subspaces such as lines and planes passing through the origin.
For a line defined by a direction vector $\bm u$
$$l = \{ (x,y,z) \in \R^3 | (x,y,z) = \bm 0 + t \bm u \} $$
we can define the projection onto the line
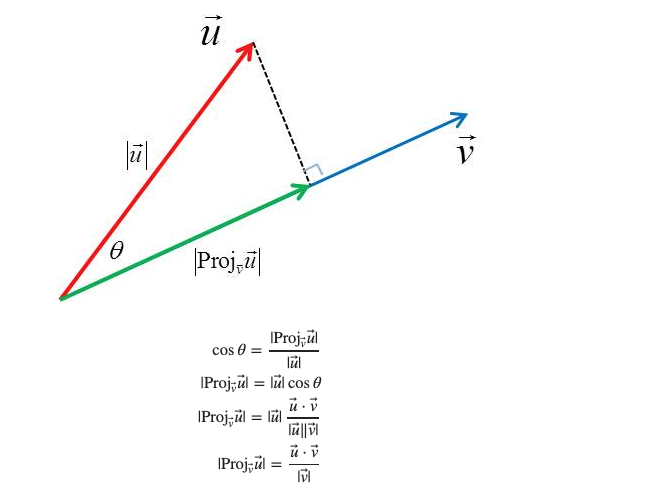 Projection of $\bm u$ onto the line $l$
Projection of $\bm u$ onto the line $l$
The space $S^\perp ≡ l^\perp$ is a plane since it consists of all the vectors that are perpendicular to the line. What is shown in the figure as a dashed line is simply the projection of $\bm u$ on the $l^\perp$ subspace,
$$l^\perp = \{ (x,y,z) \in \R^3 | \begin{bmatrix} x \\ y \\ z \end{bmatrix}^T \bm v = 0\} $$
The orthogonal space of a line with direction vector $\bm v$ is a plane with a normal vector $\bm v$. So when we project the $\bm v$ on the line we get two components one is lying on the line and is the $\Pi_l \bm u$ and the other is the vector $\bm w$ = $\Pi_{l^\perp} \bm u = \bm u - \bm v = \bm u - \Pi_{\bm v} \bm u $. The vector $\bm w$ is what remains when we remove the projected on $\bm v$ part from the $\bm u$.
The Four Fundamental Subspaces #
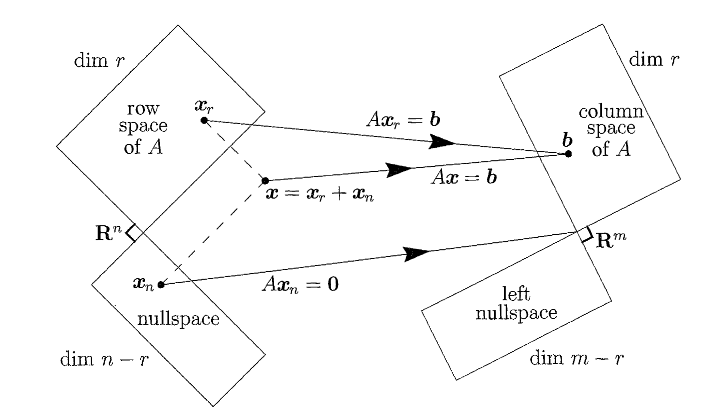
The fundamental theorem of Linear Algebra specifies the effect of the multiplication operation of the matrix and a vector ($A\mathbf{x}$). The matrix gives raise to 4 subspaces:
- The column space of $A$, denoted by $\mathcal{R}(A)$, with dimension $r$.
- The nullspace of $A$, denoted by $\mathcal{N}(A)$, with dimension $n-r$.
- The row space of $A$ which is the column space of $A^T$, with dimension $r$
- The left nullspace of $A$, which is the nullspace of $A^T$, denoted by $\mathcal{N}(A^T)$, with dimension $m-r$.
The real action that the matrix performs is to transform its row space to its column space.
The type of matrices that are common in ML are those that the number of rows $m$ representing observations is much larger than the number of columns $n$ that represent features. We will call these matrices “tall” for obvious reasons. Let us consider one trivial but instructive example of the smallest possible “tall” matrix:
$$\begin{bmatrix} a_{11} & a_{12} \\ a_{21} & a_{22} \\ a_{31} & a_{32} \end{bmatrix} = \begin{bmatrix} 1 & 0 \\ 5 & 4 \\ 2 & 4 \end{bmatrix}$$
In ML we are usually concerned with the problem of learning the weights $x_1, x_2$ that will combine the features and result into the given target variables $\mathbf{b}$. The notation here is different and we have adopted the notation of many linear algebra textbooks.
$$ \begin{bmatrix} 1 & 0 \\ 5 & 4 \\ 2 & 4 \end{bmatrix} \begin{bmatrix} x_1 \\ x_2 \end{bmatrix} = \begin{bmatrix} b_1 \\ b_2 \\ b_3 \end{bmatrix}$$
To make more explicit the combination of features we can write,
$$ x_1 \begin{bmatrix} 1 \\ 5 \\ 2 \end{bmatrix} + x_2 \begin{bmatrix} 0 \\ 4 \\ 4 \end{bmatrix} = \begin{bmatrix} b_1 \\ b_2 \\ b_3 \end{bmatrix}$$
Since $m=3 > n=2$, we have more equations than unknowns we in general we have no solutions - a system with $m > n$ will be solvable only for certain right hand sides $\mathbf{b}$. Those are all the vectors $\mathbf{b}$ that lie in the column space of $A$.
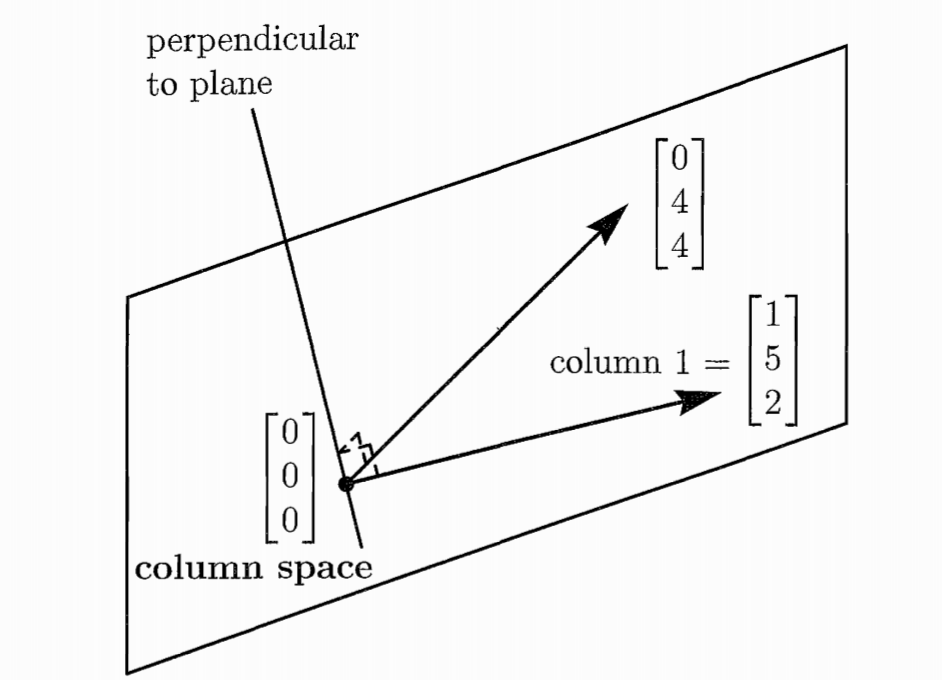
In this example, as shown in the picture $\mathbf{b}$ must lie in the plane spanned by the two columns of $A$. The plane is a subspace of $\mathbb{R}^m=\mathbb{R}^3$ in this case.
Now instead of looking at what properties $\mathbf{b}$ must have for the system to have a solution, lets look at the dual problem i.e. what weights $\mathbf{x}$ can attain those $\mathbf{b}$. The right-hand side $\mathbf{b}=0$ always allows the solution $\mathbf{x}=0$ The solutions to $A \mathbf{x} = \mathbf{0}$ form a vector space - the nullspace $\mathcal{N}(A)$. The nullspace is also called the kernel of matrix $A$ and the its dimension $n-r$ is called the nullity.
$\mathcal{N}(A)$ is a subspace of $\mathbb{R}^n=\mathbb{R}^2$ in this case. For our specific example,
$$ x_1 \begin{bmatrix} 1 \\ 5 \\ 2 \end{bmatrix} + x_2 \begin{bmatrix} 0 \\ 4 \\ 4 \end{bmatrix} = \begin{bmatrix} 0 \\ 0 \\ 0 \end{bmatrix}$$
the only solution that can satisfy this set of homogenous equations is: $\mathbf{x}=\mathbf{0}$ and this means that the null space contains only the zero vector and this
Two vectors are independent when their linear combination cannot be zero, unless both $x_1$ and $x_2$ are zero. The columns of $A$ are therefore linearly independent and they span the column space. They have therefore all the properties needed for them to constitute a set called the basis for that space and we have two basis vectors (the rank is $r=2$ in this case). The dimension of the column space is in fact the same as the dimension of the row space ($r$) and the mapping from row space to column space is in fact invertible. Every vector $\mathbf{b}$ comes from one and only one vector $\mathbf{x}$ of the row space ($\mathbf{x}_r$). And this vector can be found by the inverse operation - noting that only the inverse $A^{-1}$ is the operation that moves the vector correctly from the column space to the row space. The inverse exists only if $r=m=n$ - this is important as in most ML problems we are dealing with “tall” matrices with the number of equations much larger than the number of unknowns which makes the system inconsistent (or degenerate).
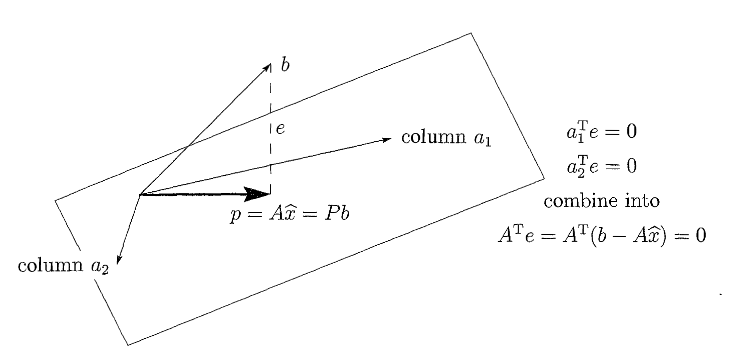 Projection onto the column space
Projection onto the column space
Geometrically you can think about the basis vectors as the axes of the space. However, if the axes are not orthogonal, calculations will tend to be complicated not to mention that we usually attribute to each vector of the basis to have length one (1.0).
Eigenvalues and Eigenvectors #
The following video gives an intuitive explanation of eigenvalues and eigenvectors and its included here due to its visualizations that it offers. The video must be viewed in conjunction with Strang’s introduction
During the lecture we will go through an example from how your brain processes the sensory input generated by the voice of the lecturer(unless you are already asleep by that time) to combine optimally the sound from both your ears.
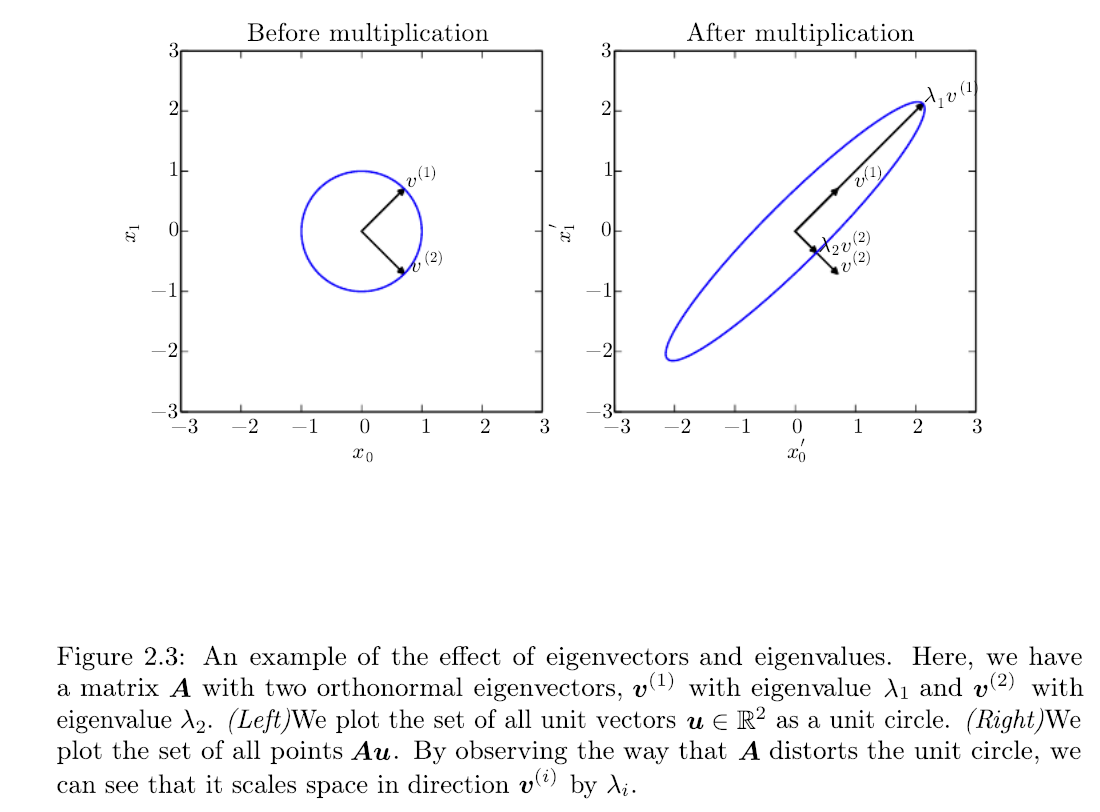
A geometric interpretation of the eigenvectors and eigenvalues is given in the following figure: