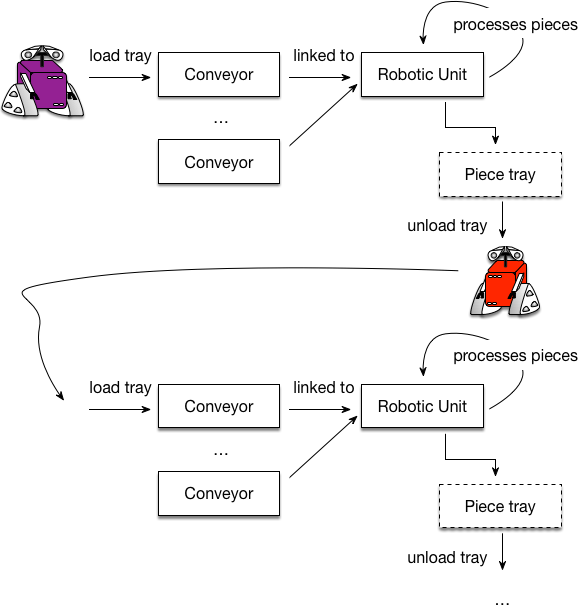
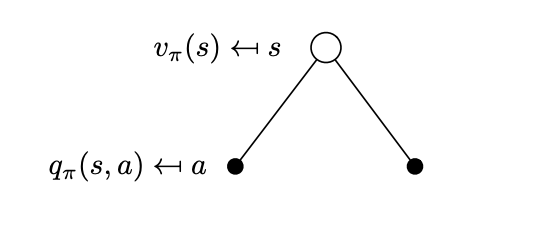
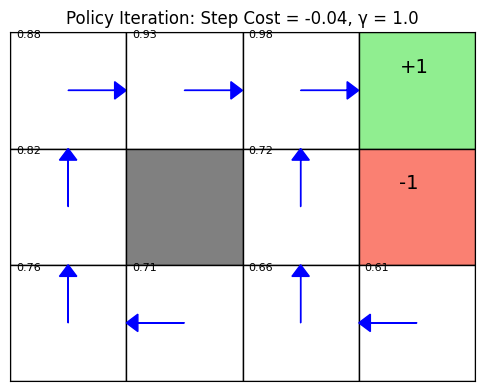
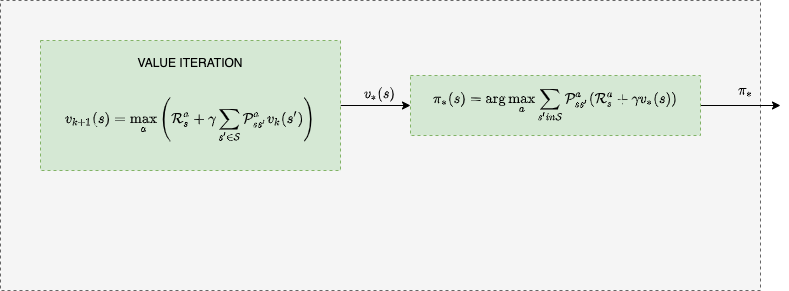
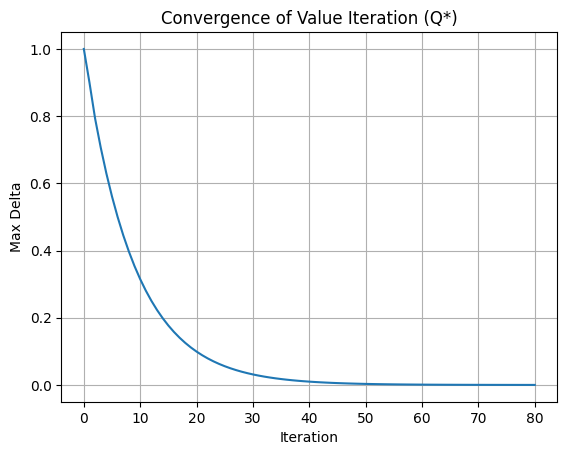
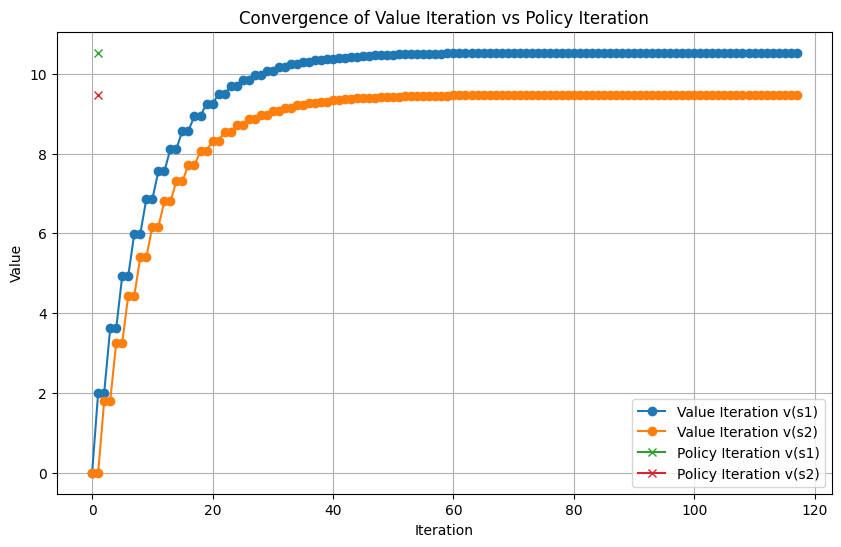
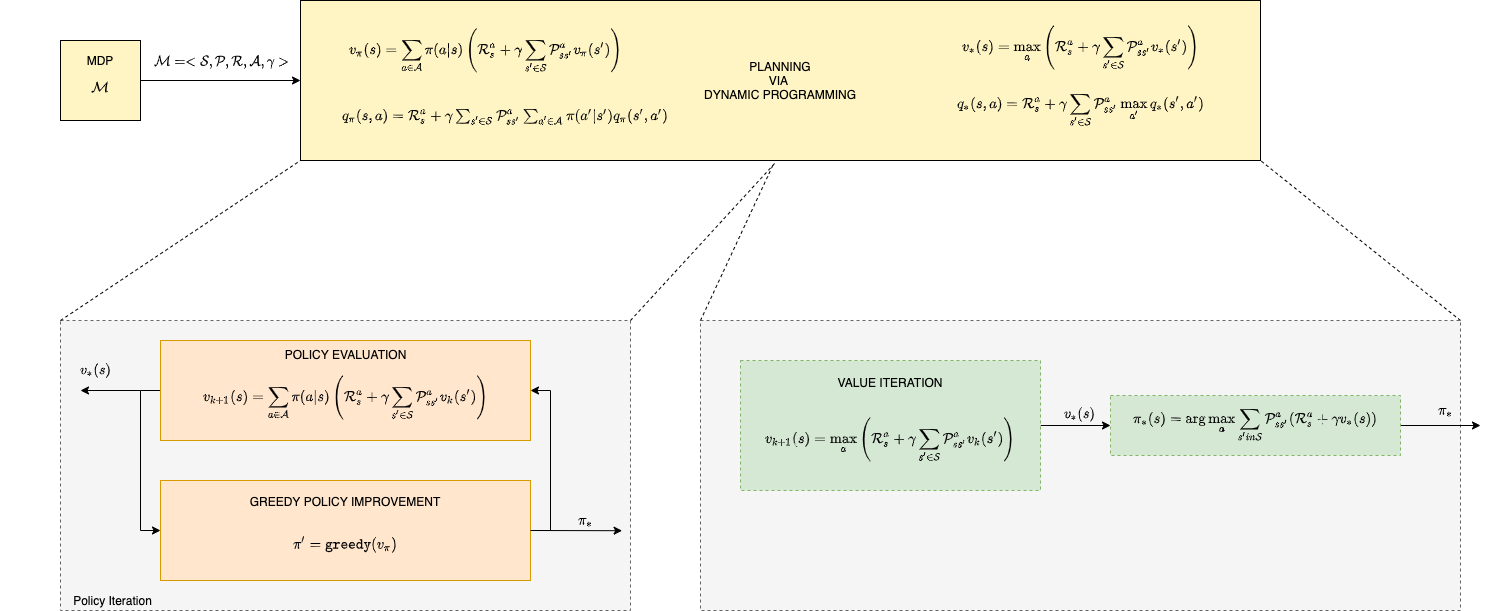
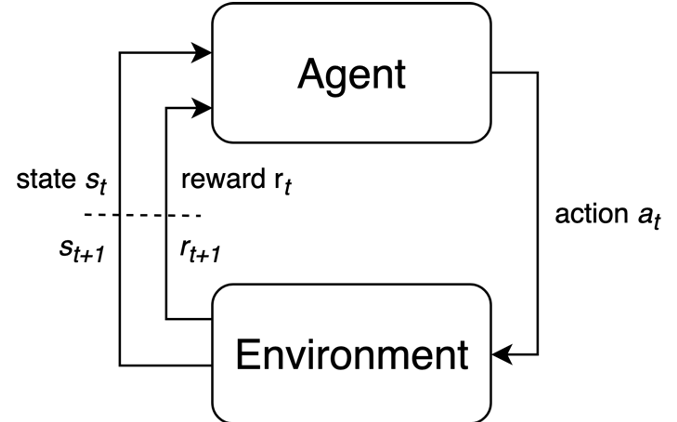
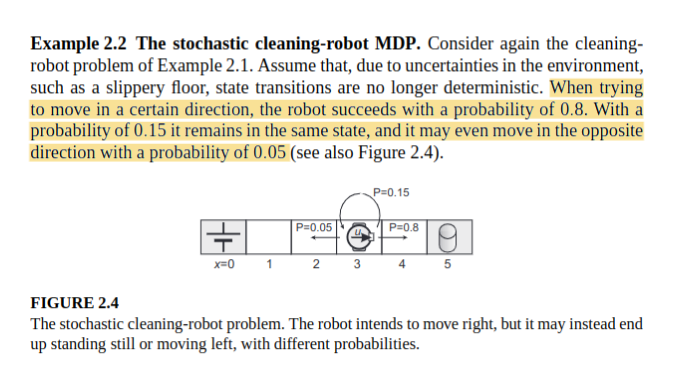
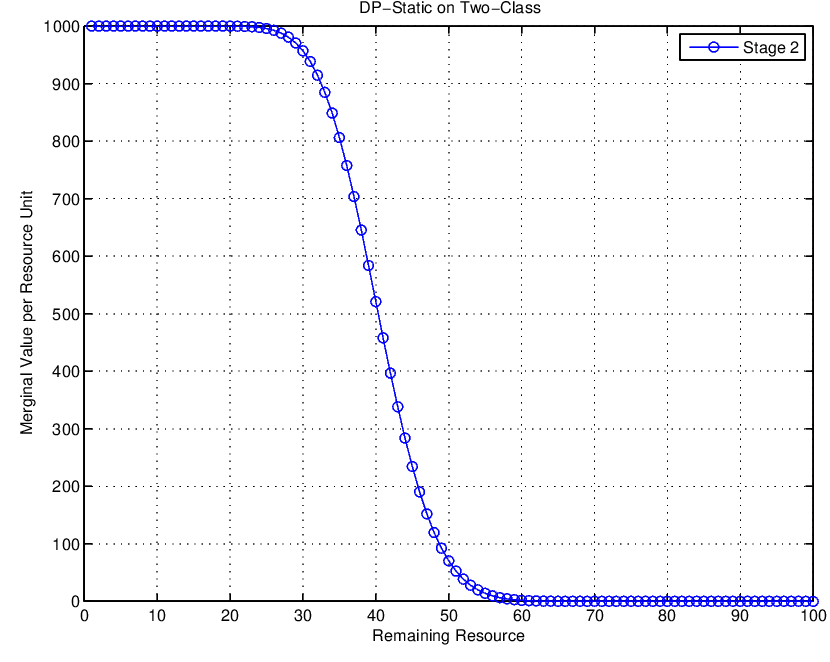
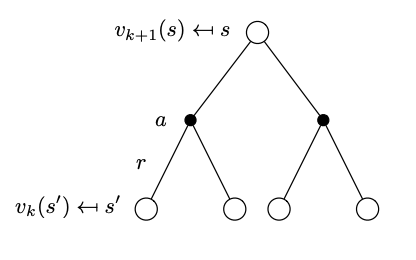
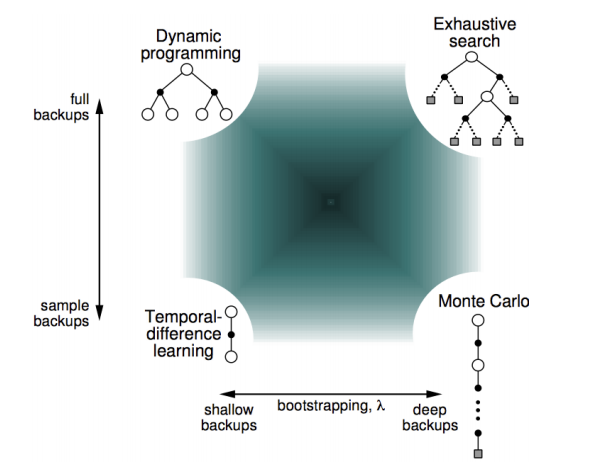
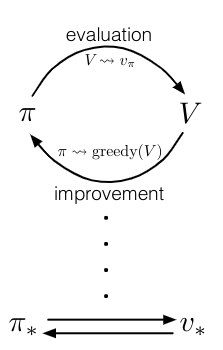
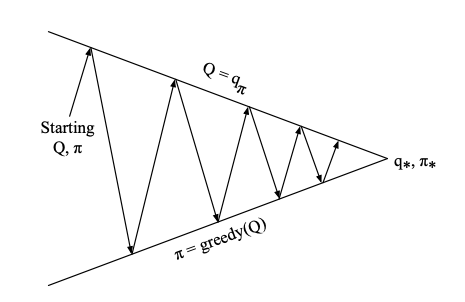
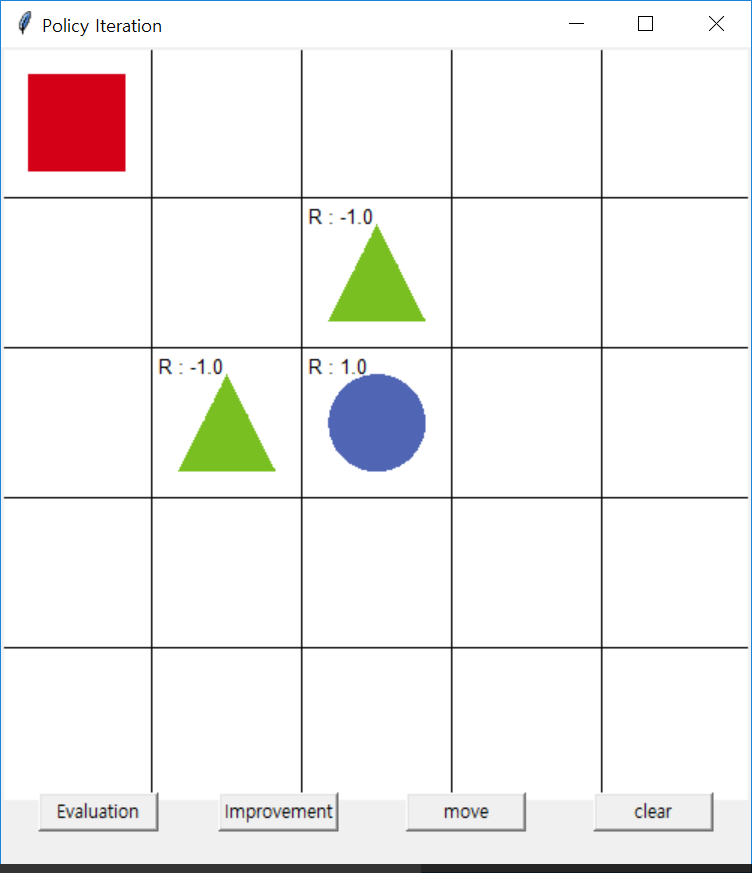
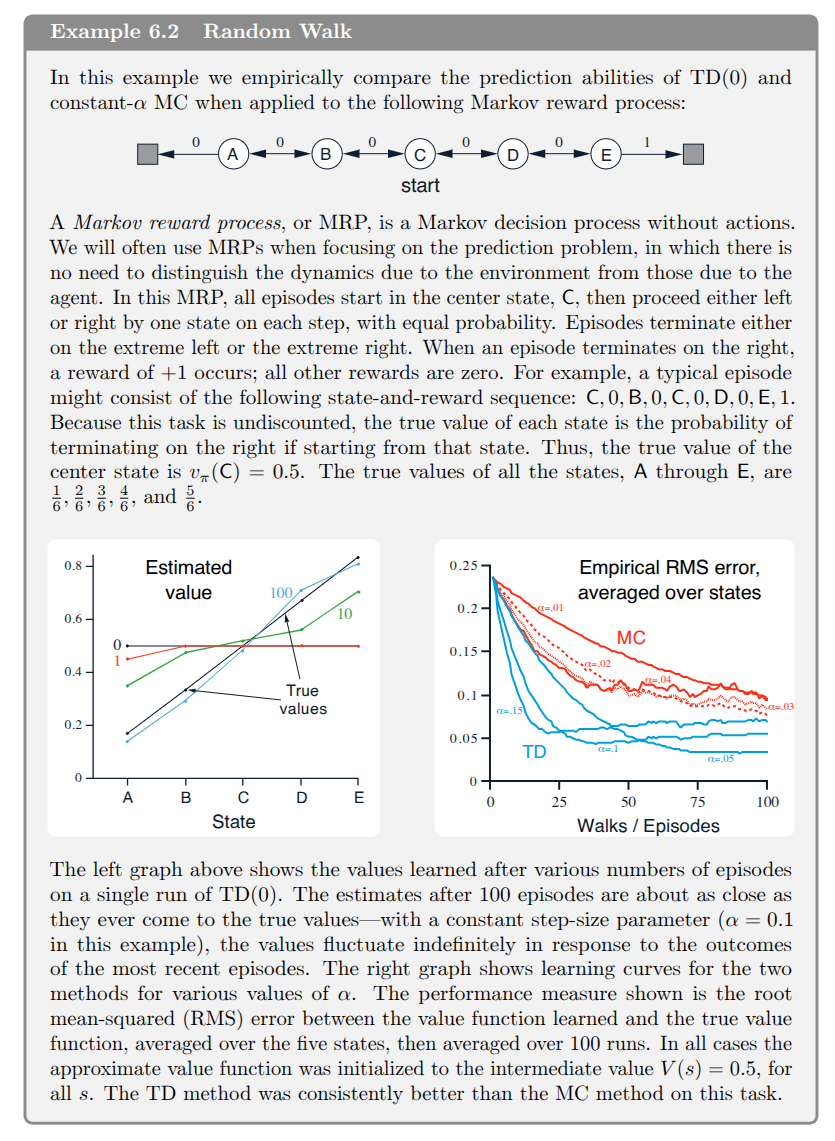
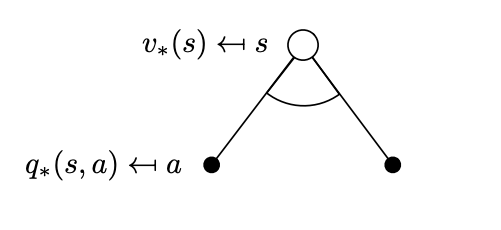Start Here
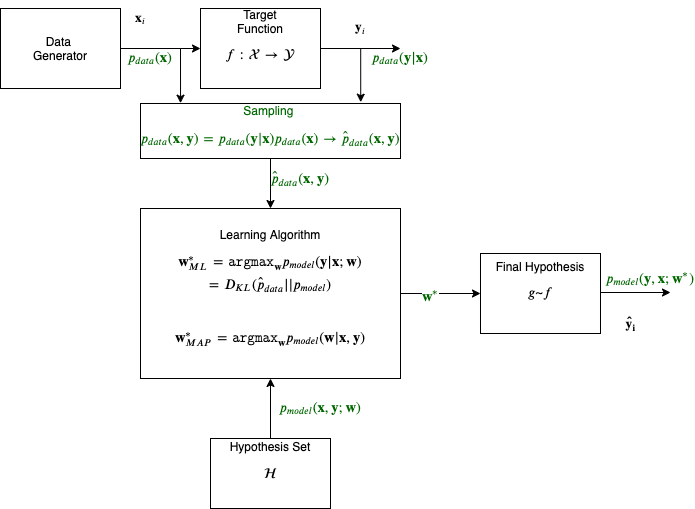
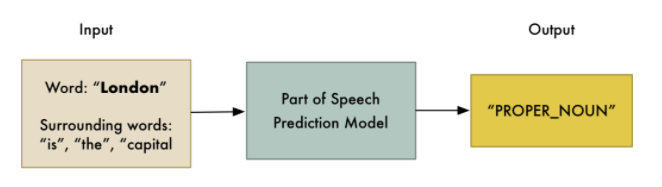
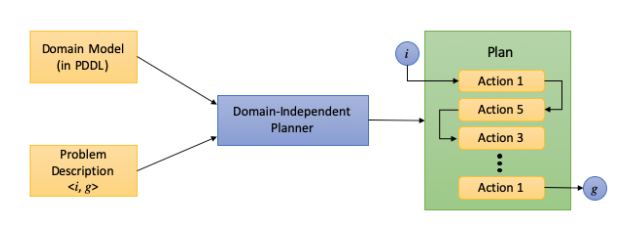
The supervised learning problem statement.
import torch from torchvision import datasets, transforms, models, ops, io from torchvision.models.detection.mask_rcnn import MaskRCNNPredictor from torchvision.models.detec…
hotel
conference
walk
bear
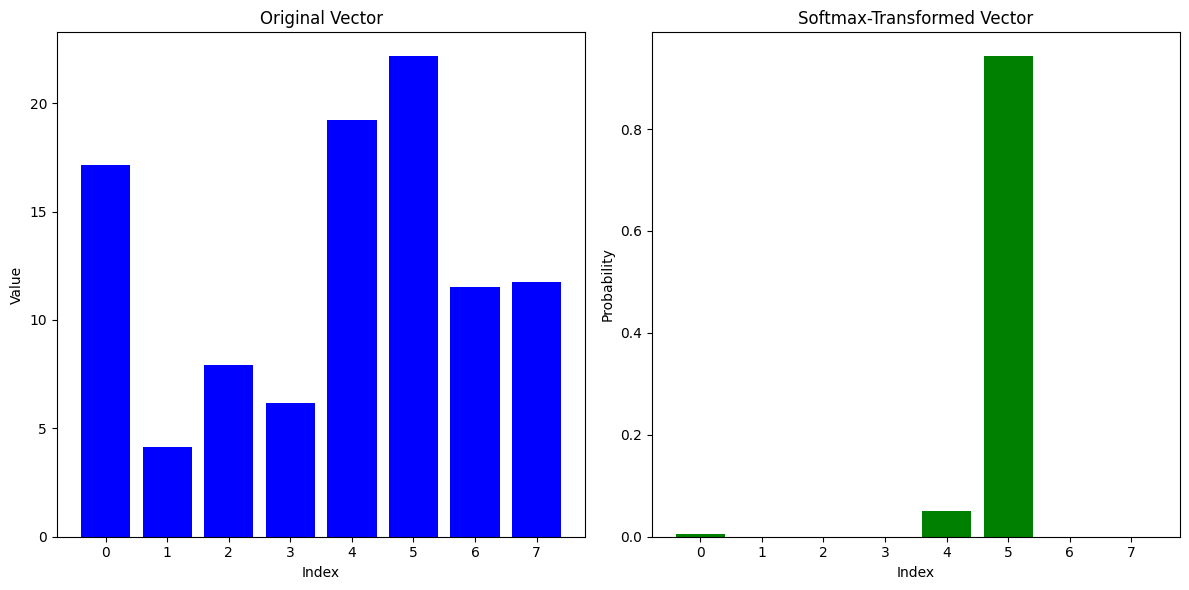
import numpy as np import matplotlib.pyplot as plt # Creating an 8-element numpy vector with random gaussian values # vector = np.random.randn(8) vector = np.array([0.17148…
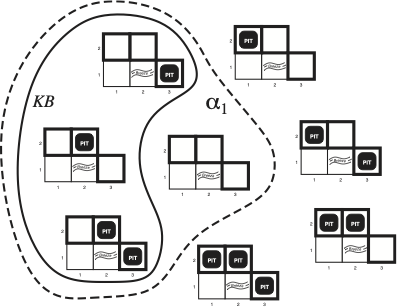
unified_planning.plot
# Uncomment to run the code locally # !git clone https://github.com/dennybritz/reinforcement-learning.git reinforcement_learning
Cloning into…
# aima_gridworld_env.py import gymnasium as gym from gymnasium import spaces from minigrid.core.grid import Grid from minigrid.minigrid_env import MiniGridEnv class AIMAGr…
""" Trains an agent with (stochastic) Policy Gradients on Pong. Uses OpenAI Gym. """ import numpy as np import cPickle as pickle import gym # hyperparameters H = 200 #…