import numpy as np
import random
from collections import defaultdict
import sys
import os
os.environ['PYTHONWARNINGS'] = 'ignore' # Suppress warnings
sys.path.insert(0, './environment')
from environment import Env
import matplotlib.pyplot as plt
import seaborn as sns
from tqdm import tqdm
# SARSA agent learns every time step from the sample <s, a, r, s', a'>
class SARSAgent:
def __init__(self, actions):
self.actions = actions
self.learning_rate = 0.01
self.discount_factor = 0.9
self.epsilon = 0.1
self.q_table = defaultdict(lambda: [0.0, 0.0, 0.0, 0.0])
# with sample <s, a, r, s', a'>, learns new q function
def learn(self, state, action, reward, next_state, next_action):
current_q = self.q_table[state][action]
next_state_q = self.q_table[next_state][next_action]
new_q = (current_q + self.learning_rate *
(reward + self.discount_factor * next_state_q - current_q))
self.q_table[state][action] = new_q
# get action for the state according to the q function table
# agent pick action of epsilon-greedy policy
def get_action(self, state):
if np.random.rand() < self.epsilon:
# take random action
action = np.random.choice(self.actions)
else:
# take action according to the q function table
state_action = self.q_table[state]
action = self.arg_max(state_action)
return action
@staticmethod
def arg_max(state_action):
max_index_list = []
max_value = state_action[0]
for index, value in enumerate(state_action):
if value > max_value:
max_index_list.clear()
max_value = value
max_index_list.append(index)
elif value == max_value:
max_index_list.append(index)
return random.choice(max_index_list)
SARSA Gridworld Example
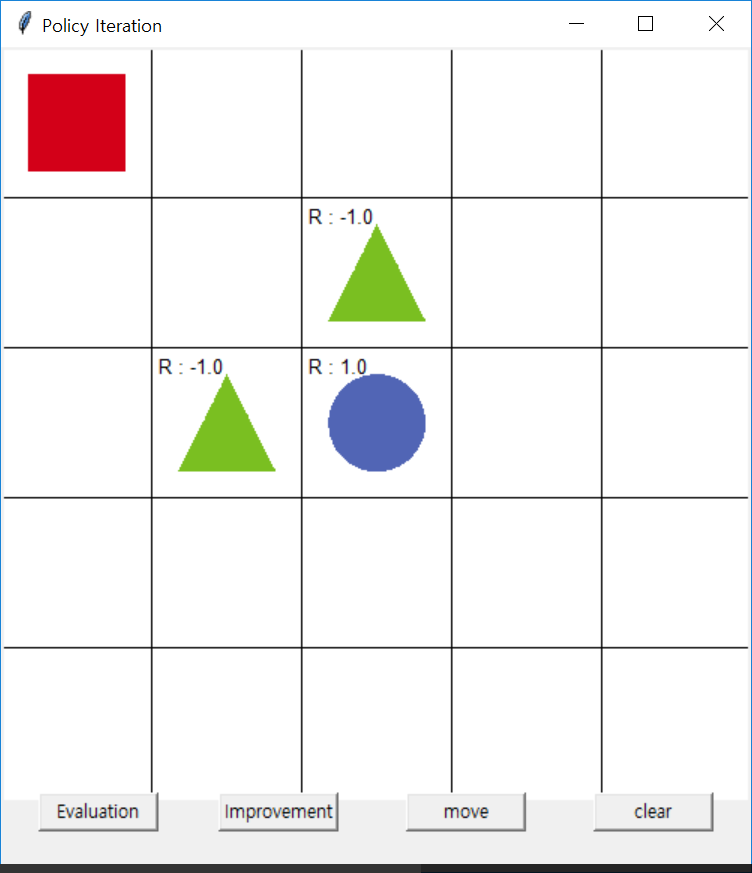 SARSA Gridworld
SARSA Gridworld
if __name__ == "__main__":
env = Env()
agent = SARSAgent(actions=list(range(env.n_actions)))
for episode in tqdm(range(10000), desc="Training Episodes"):
#print("Episode: ", episode)
# reset environment and initialize state
state = env.reset()
# get action of state from agent
action = agent.get_action(str(state))
while True:
# env.render() # Commented out to prevent matplotlib figure output
# take action and proceed one step in the environment
next_state, reward, done = env.step(action)
next_action = agent.get_action(str(next_state))
# with sample <s,a,r,s',a'>, agent learns new q function
agent.learn(str(state), action, reward, str(next_state), next_action)
state = next_state
action = next_action
# if episode ends, then break
if done:
breakTraining Episodes: 0%| | 0/10000 [00:00<?, ?it/s]Training Episodes: 100%|██████████| 10000/10000 [03:33<00:00, 46.89it/s]
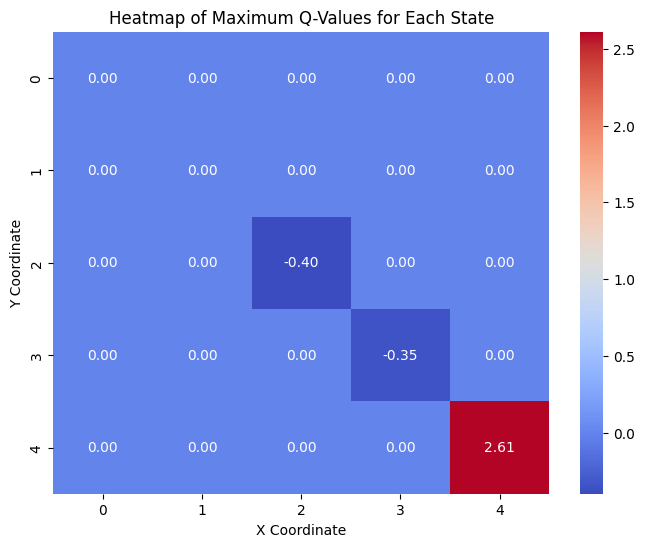
def plot_q_values(q_table):
# Create a grid to store the maximum Q-value for each state
q_values_grid = np.zeros((5, 5))
for state, actions in q_table.items():
try:
state_coords = eval(state) # Convert string back to list
q_values_grid[state_coords[0], state_coords[1]] = max(actions)
except (SyntaxError, TypeError, IndexError):
# Skip invalid states
continue
# Plot the heatmap
plt.figure(figsize=(8, 6))
sns.heatmap(q_values_grid, annot=True, fmt='.2f', cmap='coolwarm', cbar=True)
plt.title('Heatmap of Maximum Q-Values for Each State')
plt.xlabel('X Coordinate')
plt.ylabel('Y Coordinate')
plt.show()
plot_q_values(agent.q_table)