Learning Examples
Supervised Learning
A couple of examples of supervised learning are shown below:
 Examples from the MNIST training dataset used for classification
Examples from the MNIST training dataset used for classification
 Zillow predicts prices for similar homes in the same market. This is a regression problem.
Zillow predicts prices for similar homes in the same market. This is a regression problem.
Semi-supervised Learning
Semi-supervised learning stands between the supervised and unsupervised methods. In semi-supervised learning we combine a small amount of labeled data with a large amount of unlabeled data during training. Semi-supervised learning can be achieved with either inductive or transductive learning. Transduction was introduced by Vladimir Vapnik in the 1990s, motivated by his view that transduction is preferable to induction since, according to him, induction requires solving a more general problem (inferring a function) before solving a more specific problem (computing outputs for new cases).
Active Learning
In many practical settings we simply cannot afford to label /annotate all $\mathbf x$ for very large $m$, and we need to select the ones that greedily result into the biggest performance metric gain (e.g. accuracy). Deciding what examples $x$ to label for learning the final hypothesis function is called Active learning. Active learning is useful if the complexity of the underlying target function is localized – labels of some data points are more informative than others.
Unsupervised Learning
In unsupervised learning, we present a training set ${ \mathbf{x}_1, \dots, \mathbf{x}_m }$ without labels. The most common unsupervised learning method is clustering. We construct a partition of the data into a number of $K$ clusters, such that a suitably chosen loss function is minimized for a different set of input data (test).
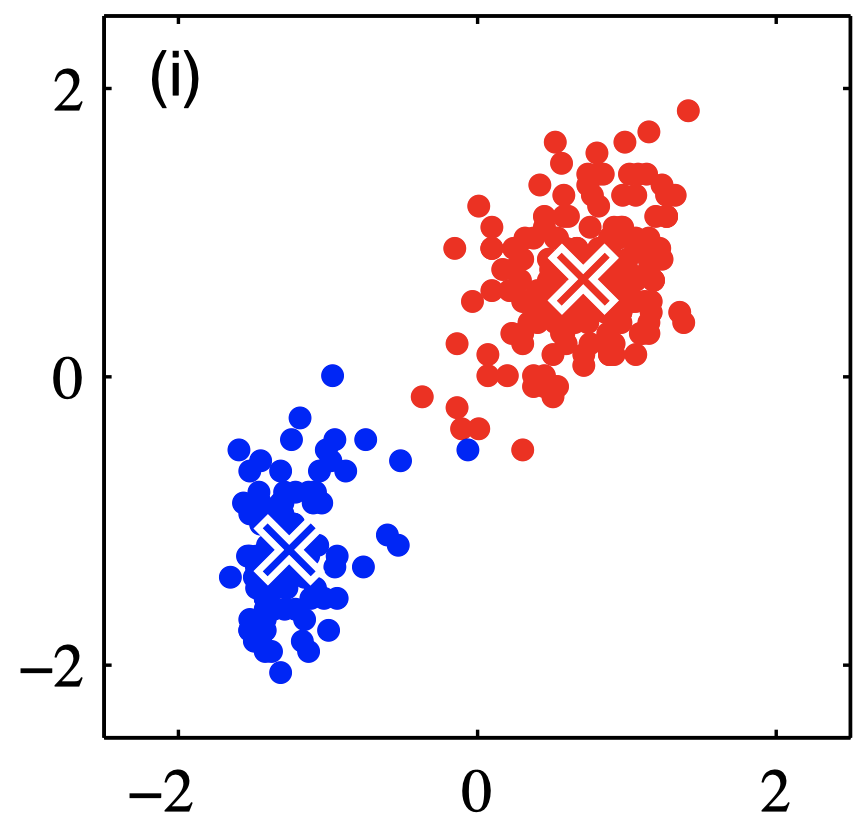 Clustering showing two classes and the exemplars per class
Clustering showing two classes and the exemplars per class
Reinforcement Learning
In reinforcement learning, a teacher is not providing a label (as in supervised learning) but rather a reward that judges whether the agent’s action results on favorable environment states. In reinforcement learning we can learn end-to-end mappings from perceptions to actions.