Introducing Erica - Your AI Tutor
You are asked to put together a system that will create an AI course tutor. Erica should be capable of answering questions, providing explanations, and assisting with learning. In this assignment we have picked the Introduction to AI as the course since we have a critical mass of material (videos, slides, web site with links to papers).
In its full implementation Erica will be able to see you, hear you and talk to you. However, for the purpose of this project and knowing how constrained student computers are, we will focus on text-based interactions only.
System Architecture
The system architecture for Rebeca consists of several key components:
User Interface (UI): you need to use a chat application and you can choose any chat interface of your liking provided you use it only for the text input and answer output. For example OpenWebUI may have a RAG interfacing capability but you are not allowed to use that. You are also not allowed to use AI browsers recently introduced by Perplexity (Comet), OpenAI and others.
LLM Server: The chat should be able to connect to a local Ollama or LM Studio server instance and be configured to use the qwen2.5 model. If your hardware simply does not allow you to run locally any version of the Qwen2.5 models you can use a remote API to access it and we recommend OpenRouter.
GraphRAG Retrieval Augmented Generation. It combines the strengths of retrieval-based and generation-based models, enabling the model to retrieve relevant information from a large corpus and generate a coherent domain-specific response. The individual components are shown in Figure 1.
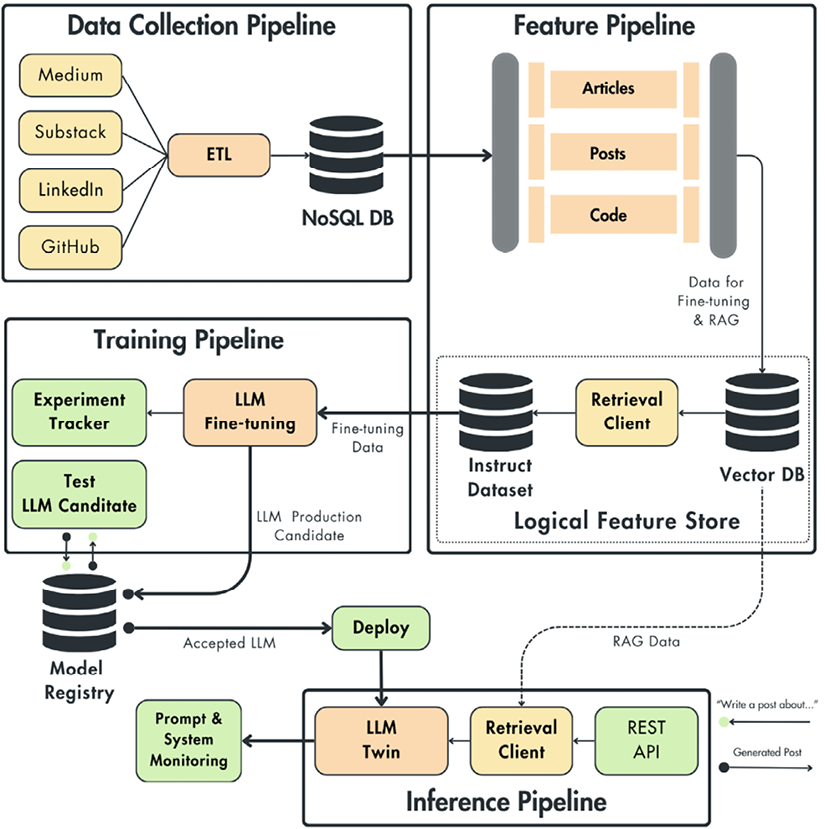
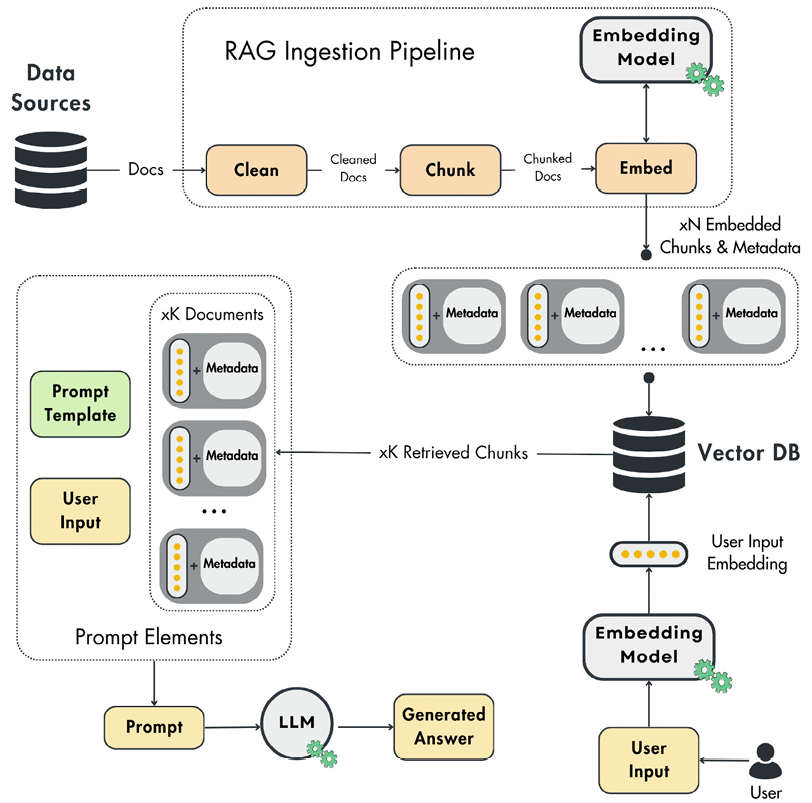
You will find good description of what a baseline RAG is, in this book. You are not using the book’s implementation since this RAG system in fact implements a baseline approach that is not compatible with what we are after:
What we need is called GraphRAG and depends on a Knowledge Graph. It aligns well with our setting: building a knowledge graph of concepts and using it for retrieval and generation in a tutor. You will use this codebase as a starting point for your implementation. Langchain also offers an implementation you can use if you are familiar with that ecosystem.
GraphRAG works at a high level as follows:
Chunking
Ask an LLM to extract entities and relations from each chunk
Write nodes/edges into a graph store (NetworkX by default; Neo4j optional)
Cluster the graph and write “community reports” (summaries) for each cluster
At query time, retrieve either a local neighborhood or community summaries and generate the answer with citations
Project Milestones
M1: Environment and Tooling Milestone
This is self explanatory - you need to have at least a docker compose file that will create the development environment for the GraphRAG system.
M2: Ingestion Milestone
Here we implement the ingestion pipeline that will ingest multiple media sources such as the course web site, youtube videos related to the course and the slides. The ingestion pipeline should be able to store the raw data in a database of your choice. Ensure you have a notebook cell / markdown file that prints all the URLs that you have ingested either explicitly or via a database query.
You can use Mongodb for storing the raw data or simply use files in a directory structure.
M3: GraphRAG Construction Milestone
Implement the Knowledge Graph.
The KG will have as Nodes the following relations:
concept: {id, title, difficulty, aliases, definitions}
resource: {type ∈ {pdf, slide, video, web}, span, timecodes}
example: worked example snippetsand as Edges the following relations:
prereq_of(u → v) [DAG used by the planner]
explains(resource → concept)
exemplifies(example → concept)
near_transfer(concept ↔ concept) [siblings, contrasts_with, is_a, part_of]When a student masters concept c1 (say, Jensen’s inequality), you want to test whether that knowledge transfers to a closely related context c2 for example, the variational lower bound (ELBO), which uses Jensen’s inequality inside its derivation. If the student can apply the idea in this slightly new situation, we say the learner has achieved near transfer - its a term that we use in pedagogy to effectively mean some form of hierarchical / prerequisite concept relationship.
Present elements of the KG that highlight a concept and its relationships to other concepts, resources, and examples. You can use a notebook for such visualizations.
M4: Query and Generation Milestone
Given a user query \(q\), turn it into a set of candidate concepts and map those concepts (nodes) into subgraphs that will be used to generate the answer. You can use any method you like to do the mapping and you have to explain the rationale behind your choice. Effectively retrieval is now a subgraph selection problem where the subgraph is a small, semantically coherent neighborhood with:
prerequisite chain(s) to scaffold explanations
sibling nodes to generate near-transfer checks (although asking questions to the student is optional)
attached resources / references with exact spans (eg page numbers) and timecodes (video segments).
Finally, generate the answers using the LLM and provide references to the student. You obviously need to generate answers that go from simpler concepts to the more complex ones.
Question 1: What is attention in transformers and can you provide a python example of how it is used ?
We expect to see a response that explains the dot product self-attention, the reasoning why Q, K, V vectors are needed and a code snippet that illustrates how attention is computed in a transformer model.
Question 2: What is CLIP and how it is used in computer vision applications ?
We expect to see a response that explains encoders for text and image, the principle of contrastive loss, the dot product operation and how one-shot classification can be achieved with CLIP .
Question 3: Can you explain the variational lower bound and how it relates to Jensen’s inequality ?
We expect to see an explanation of the Jensen’s inequality, explanation of variational methods and how the variational autoencoder losses use the Jensen’s inequality.
For all questions, after each answer is provided, include the nodes that are used from the knowledge graph as well as references to the resources that were used to generate the answer.
For all questions, provide the system prompt you used. You cannot add anything to the question prompt above.
Way to proceed
Do not perfect each milestone. Get a basic version working and then iterate to improve. For example, for M3 you can start with just extracting concepts as nodes and prerequisite edges only. Then you can add resources and examples as nodes and other edge types. Produce a 360 degree view of the system first and then improve each component. Commit often and use branches for major changes.
Be extra careful if you use an LLM API from a provider - set spending limits to a low value to avoid surprises.