Boosting Workshop#
A Summary of lecture “Machine Learning with Tree-Based Models in Python “, via datacamp
toc: true
badges: true
comments: true
author: Chanseok Kang
categories: [Python, Datacamp, Machine Learning]
image: images/sgb_train.png
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
Adaboost#
Boosting: Ensemble method combining several weak learners to form a strong learner.
Weak learner: Model doing slightly better than random guessing
E.g., Dicision stump (CART whose maximum depth is 1)
Train an ensemble of predictors sequentially.
Each predictor tries to correct its predecessor
Most popular boosting methods:
AdaBoost
Gradient Boosting
AdaBoost
Stands for Adaptive Boosting
Each predictor pays more attention to the instances wrongly predicted by its predecessor.
Achieved by changing the weights of training instances.
Each predictor is assigned a coefficient \(\alpha\) that depends on the predictor’s training error
AdaBoost: Training
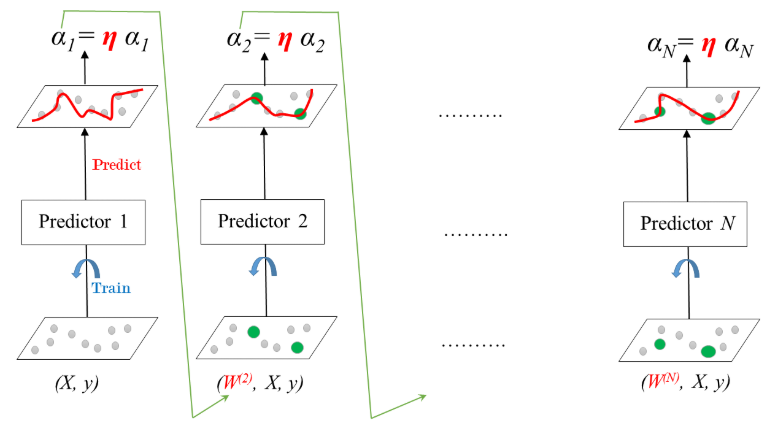
Learning rate: \(0 < \eta < 1\)
Define the AdaBoost classifier#
In the following exercises you’ll revisit the Indian Liver Patient dataset which was introduced in a previous chapter. Your task is to predict whether a patient suffers from a liver disease using 10 features including Albumin, age and gender. However, this time, you’ll be training an AdaBoost ensemble to perform the classification task. In addition, given that this dataset is imbalanced, you’ll be using the ROC AUC score as a metric instead of accuracy.
As a first step, you’ll start by instantiating an AdaBoost classifier.
from google.colab import drive
drive.mount('/content/drive')
Drive already mounted at /content/drive; to attempt to forcibly remount, call drive.mount("/content/drive", force_remount=True).
Preprocess
!pwd
indian = pd.read_csv('/content/drive/MyDrive/colab-notebooks/indian_liver_preprocessed.csv', index_col=0)
indian.head()
/content
| Age_std | Total_Bilirubin_std | Direct_Bilirubin_std | Alkaline_Phosphotase_std | Alamine_Aminotransferase_std | Aspartate_Aminotransferase_std | Total_Protiens_std | Albumin_std | Albumin_and_Globulin_Ratio_std | Is_male_std | Liver_disease | |
|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 1.247403 | -0.420320 | -0.495414 | -0.428870 | -0.355832 | -0.319111 | 0.293722 | 0.203446 | -0.147390 | 0 | 1 |
| 1 | 1.062306 | 1.218936 | 1.423518 | 1.675083 | -0.093573 | -0.035962 | 0.939655 | 0.077462 | -0.648461 | 1 | 1 |
| 2 | 1.062306 | 0.640375 | 0.926017 | 0.816243 | -0.115428 | -0.146459 | 0.478274 | 0.203446 | -0.178707 | 1 | 1 |
| 3 | 0.815511 | -0.372106 | -0.388807 | -0.449416 | -0.366760 | -0.312205 | 0.293722 | 0.329431 | 0.165780 | 1 | 1 |
| 4 | 1.679294 | 0.093956 | 0.179766 | -0.395996 | -0.295731 | -0.177537 | 0.755102 | -0.930414 | -1.713237 | 1 | 1 |
X = indian.drop('Liver_disease', axis='columns')
y = indian['Liver_disease']
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=1)
from sklearn.tree import DecisionTreeClassifier
from sklearn.ensemble import AdaBoostClassifier
# Instantiate dt
dt = DecisionTreeClassifier(max_depth=2, random_state=1)
# Instantiate ada
ada = AdaBoostClassifier(base_estimator=dt, n_estimators=180, random_state=1)
Train the AdaBoost classifier#
Now that you’ve instantiated the AdaBoost classifier ada, it’s time train it. You will also predict the probabilities of obtaining the positive class in the test set. This can be done as follows:
Once the classifier ada is trained, call the .predict_proba() method by passing X_test as a parameter and extract these probabilities by slicing all the values in the second column as follows:
ada.predict_proba(X_test)[:,1]
# Fit ada to the training set
ada.fit(X_train, y_train)
# Compute the probabilities of obtaining the positive class
y_pred_proba = ada.predict_proba(X_test)[:, 1]
Evaluate the AdaBoost classifier#
Now that you’re done training ada and predicting the probabilities of obtaining the positive class in the test set, it’s time to evaluate ada’s ROC AUC score. Recall that the ROC AUC score of a binary classifier can be determined using the roc_auc_score() function from sklearn.metrics.
from sklearn.metrics import roc_auc_score
# Evaluate test-set roc_auc_score
ada_roc_auc = roc_auc_score(y_test, y_pred_proba)
# Print roc_auc_score
print('ROC AUC score: {:.2f}'.format(ada_roc_auc))
ROC AUC score: 0.64
Gradient Boosting (GB)#
Gradient Boosted Trees
Sequential correction of predecessor’s errors
Does not tweak the weights of training instances
Fit each predictor is trained using its predecessor’s residual errors as labels
Gradient Boosted Trees: a CART is used as a base learner.
Gradient Boosted Trees for Regression: Training
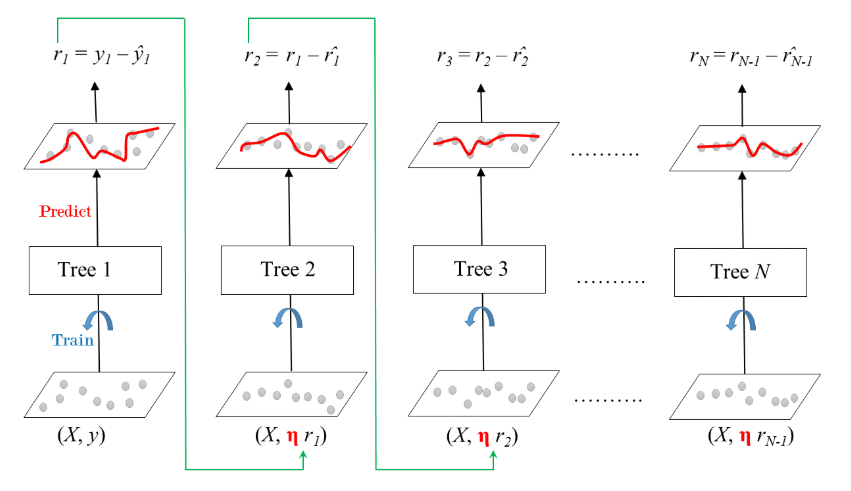
\(\eta\) (shrinkage)
Ensemble is shrinked after it is multiplied by a learning rate
Define the GB regressor#
You’ll now revisit the Bike Sharing Demand dataset that was introduced in the previous chapter. Recall that your task is to predict the bike rental demand using historical weather data from the Capital Bikeshare program in Washington, D.C… For this purpose, you’ll be using a gradient boosting regressor.
As a first step, you’ll start by instantiating a gradient boosting regressor which you will train in the next exercise.
Preprocess
bike = pd.read_csv('/content/drive/MyDrive/colab-notebooks/bikes.csv')
bike.head()
| hr | holiday | workingday | temp | hum | windspeed | cnt | instant | mnth | yr | Clear to partly cloudy | Light Precipitation | Misty | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 0 | 0 | 0 | 0.76 | 0.66 | 0.0000 | 149 | 13004 | 7 | 1 | 1 | 0 | 0 |
| 1 | 1 | 0 | 0 | 0.74 | 0.70 | 0.1343 | 93 | 13005 | 7 | 1 | 1 | 0 | 0 |
| 2 | 2 | 0 | 0 | 0.72 | 0.74 | 0.0896 | 90 | 13006 | 7 | 1 | 1 | 0 | 0 |
| 3 | 3 | 0 | 0 | 0.72 | 0.84 | 0.1343 | 33 | 13007 | 7 | 1 | 1 | 0 | 0 |
| 4 | 4 | 0 | 0 | 0.70 | 0.79 | 0.1940 | 4 | 13008 | 7 | 1 | 1 | 0 | 0 |
X = bike.drop('cnt', axis='columns')
y = bike['cnt']
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=2)
from sklearn.ensemble import GradientBoostingRegressor
# Instantiate gb
gb = GradientBoostingRegressor(max_depth=4, n_estimators=200, random_state=2)
Train the GB regressor#
You’ll now train the gradient boosting regressor gb that you instantiated in the previous exercise and predict test set labels.
# Fit gb to the training set
gb.fit(X_train, y_train)
# Predict test set labels
y_pred = gb.predict(X_test)
Evaluate the GB regressor#
Now that the test set predictions are available, you can use them to evaluate the test set Root Mean Squared Error (RMSE) of gb.
from sklearn.metrics import mean_squared_error as MSE
# Compute MSE
mse_test = MSE(y_test, y_pred)
# Compute RMSE
rmse_test = mse_test ** 0.5
# Print RMSE
print("Test set RMSE of gb: {:.3f}".format(rmse_test))
Test set RMSE of gb: 49.537
Stochastic Gradient Boosting (SGB)#
Gradient Boosting: Cons & Pros
GB involves an exhaustive search procedure
Each CART is trained to find the best split points and features.
May lead to CARTs using the same split points and maybe the same features.
Stochastic Gradient Boosting
Each tree is trained on a random subset of rows of the training data.
The sampled instances (40%-80% of the training set) are sampled without replacement.
Features are sampled (without replacement) when choosing split points
Result: further ensemble diversity.
Effect: adding further variance to the ensemble of trees.
Stochastic Gradient Boosting: Training
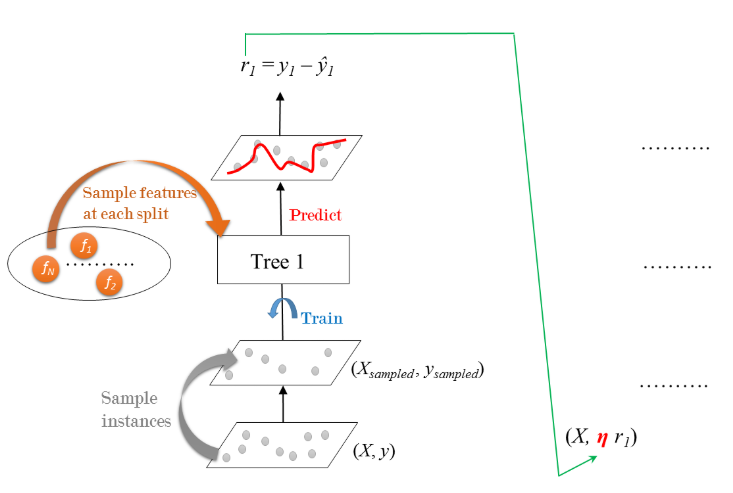
Residual errors are multiplied by the learning rate \(\eta\) and are fed to the next tree in ensemble.
Process is repeated sequentially until all the trees in the ensemble are trained.
Regression with SGB#
As in the exercises from the previous lesson, you’ll be working with the Bike Sharing Demand dataset. In the following set of exercises, you’ll solve this bike count regression problem using stochastic gradient boosting.
from sklearn.ensemble import GradientBoostingRegressor
# Instantiate sgbr
sgbr = GradientBoostingRegressor(max_depth=4, n_estimators=200, subsample=0.9,
max_features=0.75, random_state=2)
Train the SGB regressor#
In this exercise, you’ll train the SGBR sgbr instantiated in the previous exercise and predict the test set labels.
# Fit sgbr to the training set
sgbr.fit(X_train, y_train)
# Predict test set labels
y_pred = sgbr.predict(X_test)
Evaluate the SGB regressor#
You have prepared the ground to determine the test set RMSE of sgbr which you shall evaluate in this exercise.
from sklearn.metrics import mean_squared_error as MSE
# Compute test set MSE
mse_test = MSE(y_test, y_pred)
# Compute test set RMSE
rmse_test = mse_test ** 0.5
# Print rmse_test
print('Test set RMSE of sgbr: {:.3f}'.format(rmse_test))
Test set RMSE of sgbr: 47.260