Identifying Bias and Correcting for Fairness
Identifying Bias and Correcting for Fairness
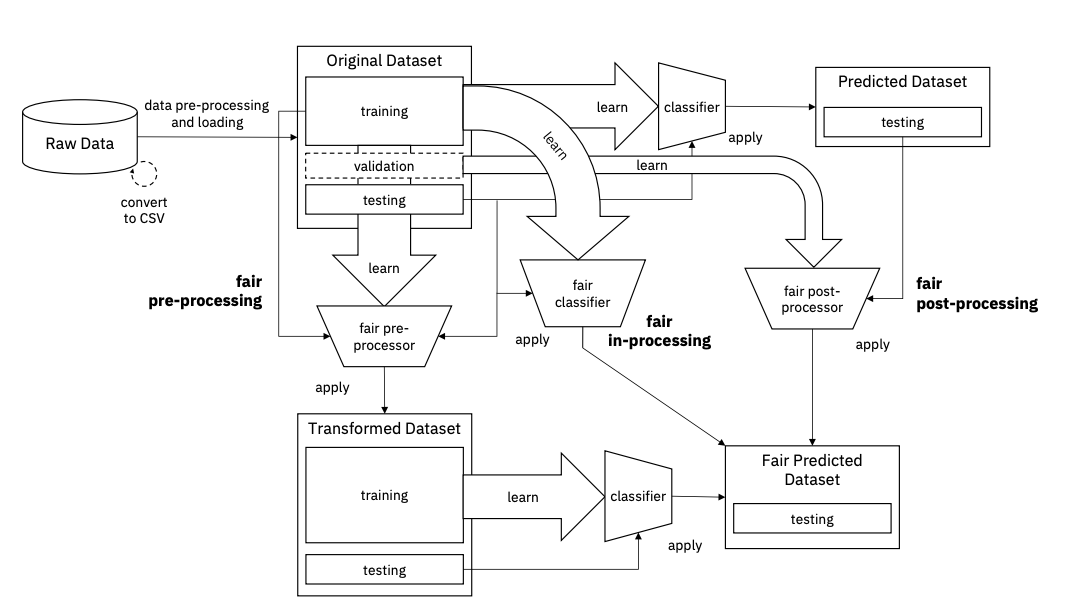 IBM’s Fairness Pipeline
IBM’s Fairness Pipeline
When you are asked to perform a data mining task (e.g. classification, regression) you are more often than not given “dirty” data that you need to glean to address a number of issues such as data errors, missing data etc. These gleaning tasks are the easy part and standard APIs do exist to enable you to analyze data for each of these issues and perform the necessary corrective actions.
The most difficult and dangerous challenge you are facing though as data scientists are hidden issues - the most prevalent of them is bias. Your task is to learn and demonstrate the usage of fair ML systems that detect and remove bias from datasets.
In this project you are given a dataset that is associated with financial credit and you are asked to use the IBM’s AI Fairness 360 toolkit in your Colab notebook environment to complete the following steps:
- Read the paper and fully understand the fairness pipeline. Write your own tutorial summary of the pipeline in a markdown file. (25 points)
- Execute the credit decision pipeline that is detecting age bias and removing using the reweighting algorithm and explain the findings. (25 points)
- Apply a different method for detecting and removing bias. (25 points)
- Write a thorough explanation comparing the reweighting and the method you selected. (25 points)
Feel free to incorporate in one notebook everything or to type the documentation parts in a separate markdown file.