Separating Perception and Reasoning via Neurosymbolic VQA
Purely symbolic approaches to artificial intelligence are inherently relational. Practitioners define the relations between symbols using the language of logic and mathematics, and then reason about these relations using a multitude of powerful methods, including deduction, arithmetic, and algebra. But symbolic approaches suffer from the symbol grounding problem and are not robust to small task and input variations. Other approaches, such as those based on statistical learning, build representations from raw data and often generalize across diverse and noisy conditions. However, a number of these approaches, such as deep learning, often struggle in data-poor problems where the underlying structure is characterized by sparse but complex relations.
In this project you will study the implementation of AI approaches that offer the ability to combine neural and symbolic representations in their attempt to answer the so called Visual Question-Answer task.
The approach here called NS-VQA is introducing object-level scene parsing and uses a program-based response system.
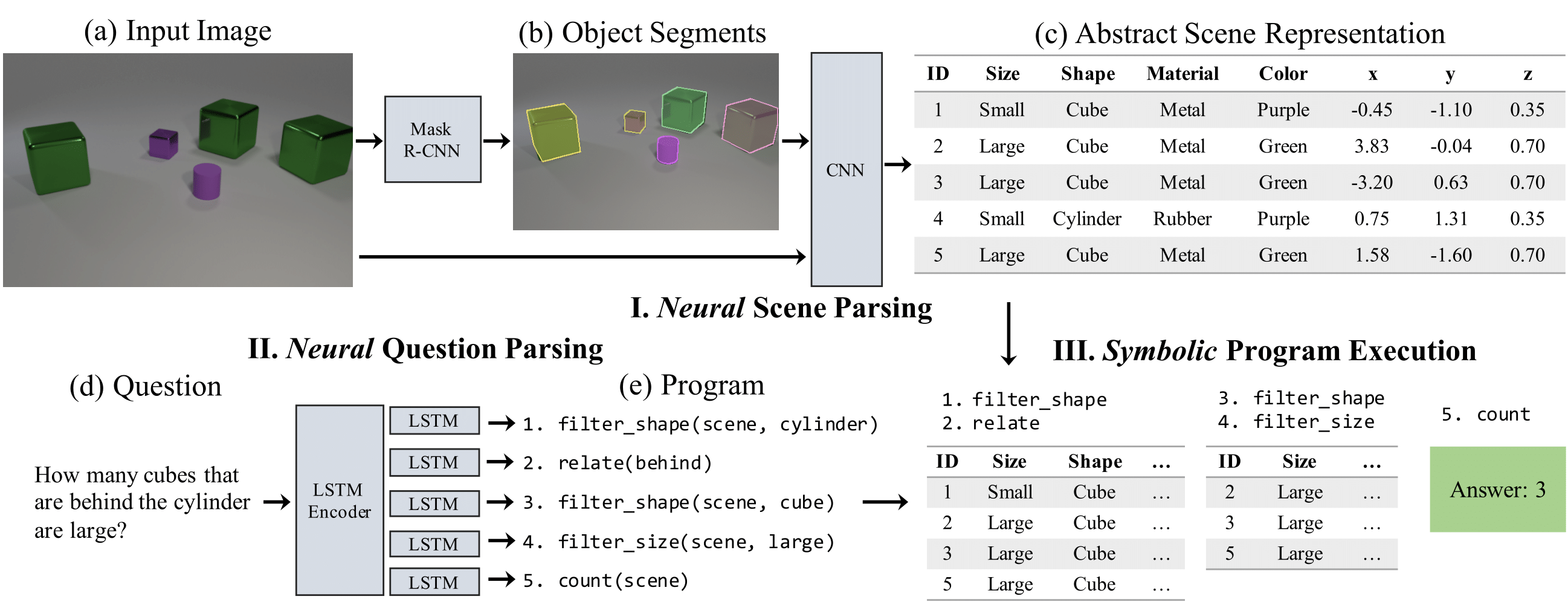
The CLEVR dataset is a synthetic photorealistic 3D dataset. You can download the published CLEVR dataset. You will apply the NeuroSymbolic VQA approach to it. Feel free to consult the implementation of the approach here but you need to bring up your own repo that can demonstrate the technique (see below) with the latest versions of the frameworks of your choice.
In all the items below, include descriptions of all impediments you will face in your attempt to replicate the results. When the paper gives you options, always select the least possible number of examples, questions etc. to ensure that the code runs in your environment. Test and obtain results only for the CLEVR dataset.
Scene Parser (10 points)
Thoroughly explain the operation of the scene parser - almost line by line.
Question Parser (10 points)
Thoroughly explain the operation of the question parser - almost line by line.
Program Executor (10 points)
Thoroughly explain the operation of the question parser - almost line by line.