Pipelines
In this section we outline some best practices for building machine learning pipelines that take full advantage of cloud-native architectures and therefore can scale across many backend instances. There are many pipelines that implement many orchestration protocols that are needed for a model to be produced and subsequently served.
We will use as a starting point the TFX implementation as described by Baylor et al. (2017) to establish some baseline terminology.
The four essential pipelines
At a functional level we can focus on Figure 1 which shows components needed to build and operate a machine learning model.
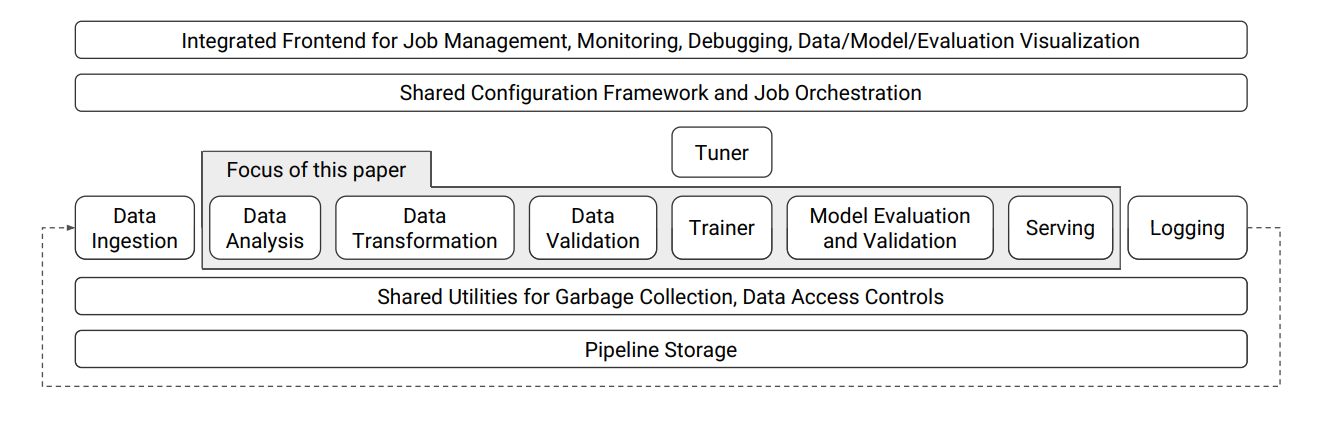
Therein we can distinguish four essential pipelines as shown in Figure 2. Note that the arrows that connect them together they are not necessarily linear, but they can be executed in parallel or in a different order as mandated by the training protocol. Also its worth noting that there are external functions not shown in this simple illustration such as systems that can change the model architecture via, for example, neural archirtecture search as described by Elsken, Metzen, and Hutter (2018) or the parameters of the model via reinforcement learning as described by Lambert et al. (2022).

Open source efforts
Due to the complexity of these platforms and a common interest to amortise their expenses to build and operate them, industrial players are partnering to define these components in open source communities. Its worthwhile to look at the landscape produced by the Linux Foundation “LF AI & Data Landscape” (n.d.) to appreciate the enormous collaborative effort in these communities on one hand and to be able to map which vendor is behind which component or tool on the other.