One of the most popular visualization methods is the Gradient weighted Class Activation Mapping (Grad-CAM) that uses the class-specific gradient information flowing into the final convolutional layer of a CNN to produce a coarse localization map of the important regions in the image.
In most instances we need to have an evaluation of robustness of a CNN to occlusions. This is quite important for video surveillance systems. To achieve that, we mask a part of the image (using a small square patch placed randomly) and observe if the prediction is still correct, on average, the network is robust. The area in the image that is the warmest (i.e., red) has the most effect on the prediction when occluded as shown below.
Occlusion Sensitivity
Visualizing heatmaps of class activation
We will introduce one more visualization technique, one that is useful for understanding which parts of a given image led a convnet to its final classification decision. This is helpful for “debugging” the decision process of a convnet, in particular in case of a classification mistake. It also allows you to locate specific objects in an image.
This general category of techniques is called “Class Activation Map” (CAM) visualization, and consists in producing heatmaps of “class activation” over input images. A “class activation” heatmap is a 2D grid of scores associated with an specific output class, computed for every location in any input image, indicating how important each location is with respect to the class considered. For instance, given a image fed into one of our “cat vs. dog” convnet, Class Activation Map visualization allows us to generate a heatmap for the class “cat”, indicating how cat-like different parts of the image are, and likewise for the class “dog”, indicating how dog-like differents parts of the image are.
The specific implementation we will use is the one described in Grad-CAM: Why did you say that? Visual Explanations from Deep Networks via Gradient-based Localization. It is very simple: it consists in taking the output feature map of a convolution layer given an input image, and weighing every channel in that feature map by the gradient of the class with respect to the channel. Intuitively, one way to understand this trick is that we are weighting a spatial map of “how intensely the input image activates different channels” by “how important each channel is with regard to the class”, resulting in a spatial map of “how intensely the input image activates the class”.
We will demonstrate this technique using the pre-trained VGG16 network again:
from keras.applications.vgg16 import VGG16K.clear_session()# Note that we are including the densely-connected classifier on top;# all previous times, we were discarding it.model = VGG16(weights='imagenet')
Downloading data from https://github.com/fchollet/deep-learning-models/releases/download/v0.1/vgg16_weights_tf_dim_ordering_tf_kernels.h5
548380672/553467096 [============================>.] - ETA: 0s
Let’s consider the following image of two African elephants, possible a mother and its cub, strolling in the savanna (under a Creative Commons license):
elephants
Let’s convert this image into something the VGG16 model can read: the model was trained on images of size 224x244, preprocessed according to a few rules that are packaged in the utility function keras.applications.vgg16.preprocess_input. So we need to load the image, resize it to 224x224, convert it to a Numpy float32 tensor, and apply these pre-processing rules.
from keras.preprocessing import imagefrom keras.applications.vgg16 import preprocess_input, decode_predictionsimport numpy as np# The local path to our target imageimg_path ='images/creative_commons_elephant.jpg'# `img` is a PIL image of size 224x224img = image.load_img(img_path, target_size=(224, 224))# `x` is a float32 Numpy array of shape (224, 224, 3)x = image.img_to_array(img)# We add a dimension to transform our array into a "batch"# of size (1, 224, 224, 3)x = np.expand_dims(x, axis=0)# Finally we preprocess the batch# (this does channel-wise color normalization)x = preprocess_input(x)
Thus our network has recognized our image as containing an undetermined quantity of African elephants. The entry in the prediction vector that was maximally activated is the one corresponding to the “African elephant” class, at index 386:
np.argmax(preds[0])
386
To visualize which parts of our image were the most “African elephant”-like, let’s set up the Grad-CAM process:
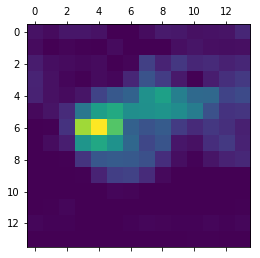
# This is the "african elephant" entry in the prediction vectorafrican_elephant_output = model.output[:, 386]# The is the output feature map of the `block5_conv3` layer,# the last convolutional layer in VGG16last_conv_layer = model.get_layer('block5_conv3')# This is the gradient of the "african elephant" class with regard to# the output feature map of `block5_conv3`grads = K.gradients(african_elephant_output, last_conv_layer.output)[0]# This is a vector of shape (512,), where each entry# is the mean intensity of the gradient over a specific feature map channelpooled_grads = K.mean(grads, axis=(0, 1, 2))# This function allows us to access the values of the quantities we just defined:# `pooled_grads` and the output feature map of `block5_conv3`,# given a sample imageiterate = K.function([model.input], [pooled_grads, last_conv_layer.output[0]])# These are the values of these two quantities, as Numpy arrays,# given our sample image of two elephantspooled_grads_value, conv_layer_output_value = iterate([x])# We multiply each channel in the feature map array# by "how important this channel is" with regard to the elephant classfor i inrange(512): conv_layer_output_value[:, :, i] *= pooled_grads_value[i]# The channel-wise mean of the resulting feature map# is our heatmap of class activationheatmap = np.mean(conv_layer_output_value, axis=-1)
For visualization purpose, we will also normalize the heatmap between 0 and 1:
Finally, we will use OpenCV to generate an image that superimposes the original image with the heatmap we just obtained:
import cv2# We use cv2 to load the original imageimg = cv2.imread(img_path)# We resize the heatmap to have the same size as the original imageheatmap = cv2.resize(heatmap, (img.shape[1], img.shape[0]))# We convert the heatmap to RGBheatmap = np.uint8(255* heatmap)# We apply the heatmap to the original imageheatmap = cv2.applyColorMap(heatmap, cv2.COLORMAP_JET)# 0.4 here is a heatmap intensity factorsuperimposed_img = heatmap *0.4+ img# Save the image to diskcv2.imwrite('images/elephant_cam.jpg', superimposed_img)
elephant cam
This visualisation technique answers two important questions:
Why did the network think this image contained an African elephant?
Where is the African elephant located in the picture?
In particular, it is interesting to note that the ears of the elephant cub are strongly activated: this is probably how the network can tell the difference between African and Indian elephants.
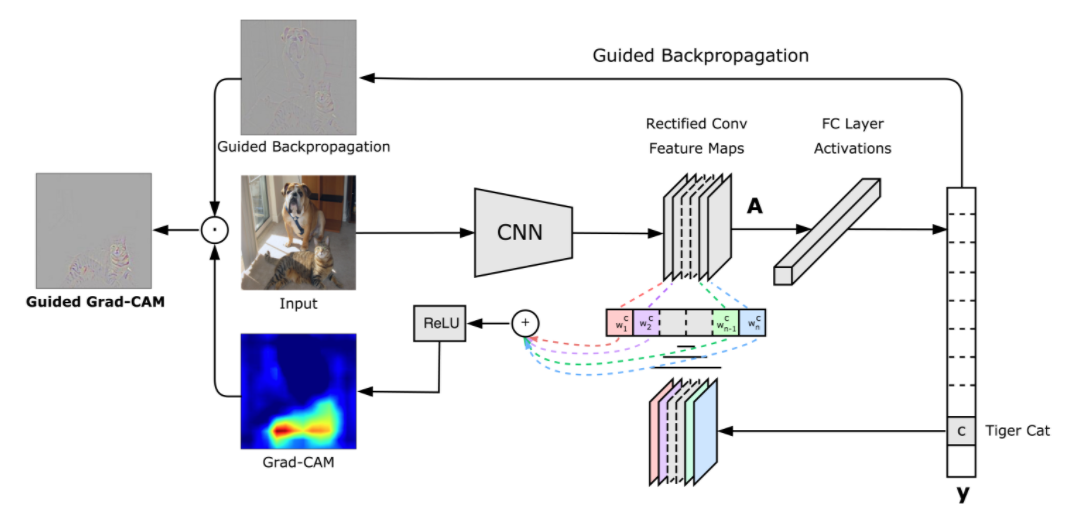 GradCAM block diagram
GradCAM block diagram
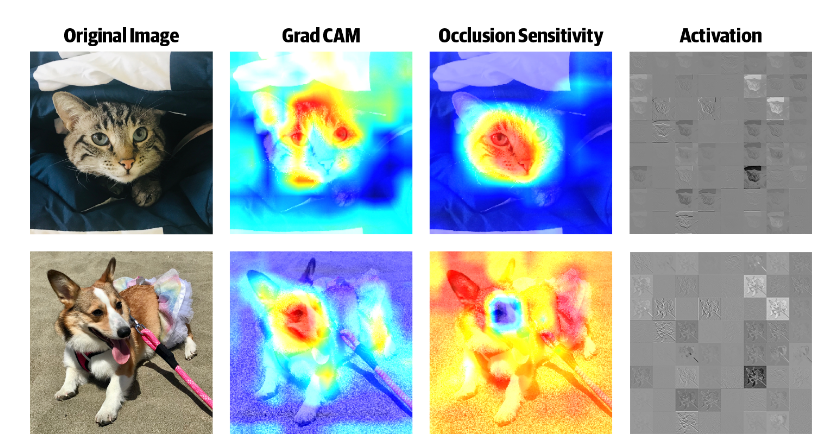 Occlusion Sensitivity
Occlusion Sensitivity