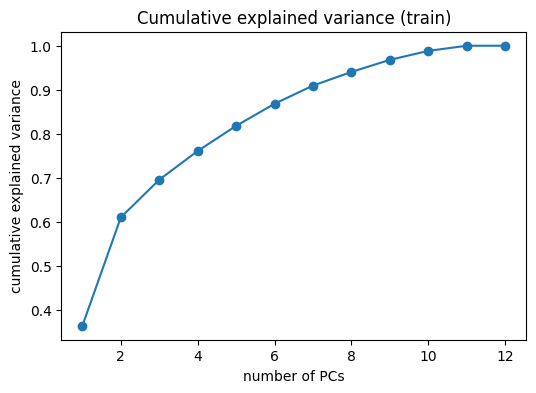
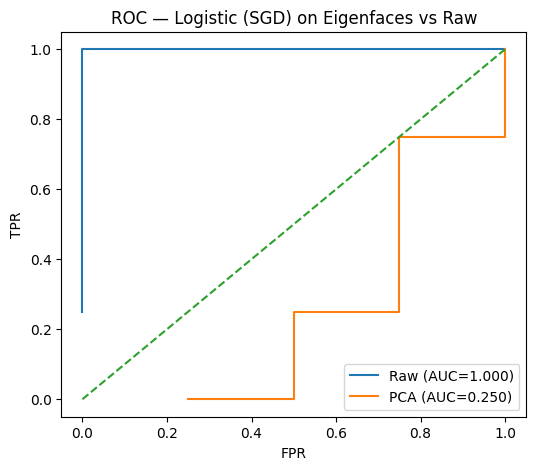
---------------------------------------------------------------------------
ValueError Traceback (most recent call last)
Cell In[8], line 6
4 for k in k_list:
5 pca_k = PCA(n_components=k, svd_solver="randomized", whiten=True, random_state=42)
----> 6 Xtr_k = pca_k.fit_transform(Xtr_std)
7 Xte_k = pca_k.transform(Xte_std)
8 _, acc_k, auc_k, _ = train_logreg_sgd(Xtr_k, y_tr, Xte_k, y_te, epochs=150, batch=16)
File /workspaces/engineering-ai-agents/.venv/lib/python3.11/site-packages/sklearn/utils/_set_output.py:316, in _wrap_method_output.<locals>.wrapped(self, X, *args, **kwargs)
314 @wraps(f)
315 def wrapped(self, X, *args, **kwargs):
--> 316 data_to_wrap = f(self, X, *args, **kwargs)
317 if isinstance(data_to_wrap, tuple):
318 # only wrap the first output for cross decomposition
319 return_tuple = (
320 _wrap_data_with_container(method, data_to_wrap[0], X, self),
321 *data_to_wrap[1:],
322 )
File /workspaces/engineering-ai-agents/.venv/lib/python3.11/site-packages/sklearn/base.py:1363, in _fit_context.<locals>.decorator.<locals>.wrapper(estimator, *args, **kwargs)
1356 estimator._validate_params()
1358 with config_context(
1359 skip_parameter_validation=(
1360 prefer_skip_nested_validation or global_skip_validation
1361 )
1362 ):
-> 1363 return fit_method(estimator, *args, **kwargs)
File /workspaces/engineering-ai-agents/.venv/lib/python3.11/site-packages/sklearn/decomposition/_pca.py:466, in PCA.fit_transform(self, X, y)
443 @_fit_context(prefer_skip_nested_validation=True)
444 def fit_transform(self, X, y=None):
445 """Fit the model with X and apply the dimensionality reduction on X.
446
447 Parameters
(...) 464 C-ordered array, use 'np.ascontiguousarray'.
465 """
--> 466 U, S, _, X, x_is_centered, xp = self._fit(X)
467 if U is not None:
468 U = U[:, : self.n_components_]
File /workspaces/engineering-ai-agents/.venv/lib/python3.11/site-packages/sklearn/decomposition/_pca.py:542, in PCA._fit(self, X)
540 return self._fit_full(X, n_components, xp, is_array_api_compliant)
541 elif self._fit_svd_solver in ["arpack", "randomized"]:
--> 542 return self._fit_truncated(X, n_components, xp)
File /workspaces/engineering-ai-agents/.venv/lib/python3.11/site-packages/sklearn/decomposition/_pca.py:717, in PCA._fit_truncated(self, X, n_components, xp)
712 raise ValueError(
713 "n_components=%r cannot be a string with svd_solver='%s'"
714 % (n_components, svd_solver)
715 )
716 elif not 1 <= n_components <= min(n_samples, n_features):
--> 717 raise ValueError(
718 "n_components=%r must be between 1 and "
719 "min(n_samples, n_features)=%r with "
720 "svd_solver='%s'"
721 % (n_components, min(n_samples, n_features), svd_solver)
722 )
723 elif svd_solver == "arpack" and n_components == min(n_samples, n_features):
724 raise ValueError(
725 "n_components=%r must be strictly less than "
726 "min(n_samples, n_features)=%r with "
727 "svd_solver='%s'"
728 % (n_components, min(n_samples, n_features), svd_solver)
729 )
ValueError: n_components=20 must be between 1 and min(n_samples, n_features)=12 with svd_solver='randomized'